13 网络爬虫简介
本章导读
本章写作过程中,借助了 AI 工具:Claude code 对话
A. 学习目标
学完本章,你应当能够:
- 用一句话解释什么是网络爬虫 (web crawler),以及它在数据分析中的作用
- 识别爬虫的合法边界,在动手之前做出合规判断
- 描述从数据采集到分析结论的完整流程,知道每一步在做什么
- 看懂 HTML 网页和 JSON 数据的基本结构
- 使用浏览器开发者工具 (DevTools) 定位目标数据的位置
- 写出一段清晰的提示词,让 AI 生成可用的爬虫代码
B. 学习路径
我们采用「AI 辅助提示词编程」的学习模式:你负责理解任务、描述需求;AI 负责生成代码;你负责阅读、验证、修改。学习过程中不要求你记忆 Python 语法,也不要求你从零写代码、自己调试 bug。这不是偷懒,而是贴近真实工作场景的技能——在银行、券商、政府机构里,能够清晰描述分析需求,往往比会手写代码更有价值。
13.1 什么是网络爬虫?
网络爬虫 (web crawler),又称网络蜘蛛 (web spider) 或网络抓取程序 (web scraper),是一种自动访问网页、提取所需数据并保存到本地的程序。
类比:你每天浏览网页时,是手动点击、阅读、复制信息。爬虫做的是同一件事,只不过是由程序自动完成,速度是人工的数千倍。
应用场景
网络爬虫的典型用途包括:
- 价格监控:电商平台商品价格的实时追踪与比价
- 舆情分析:社交媒体、新闻平台的评论与话题追踪
- 学术研究:从公开数据库批量获取研究素材
- 商业情报:竞品信息、招聘数据、房产挂牌数据等
- 政府与监管:公开政务信息、企业工商数据的汇总整理
以下是爬虫与文本分析在各行业的典型应用:
- 银行:抓取企业官网、新闻公告、行业数据,辅助信贷评估、客户画像与市场风险研判
- 券商:收集上市公司公告、行业舆情、消费评论数据,支持行业研究与投资标的分析
- 政府机构:整理公开政务数据、民生反馈、政策文本,辅助数据统计与政策效果评估
- 市场调研:从电商平台、社交媒体抓取用户评论与行为数据,支持产品优化与营销策略制定
合法边界
爬虫本身是中性工具,但使用方式决定合规性。在写代码之前,请先确认以下三点:
查看 robots.txt:在目标网站域名后加
/robots.txt(例如 https://www.dianping.com/robots.txt),查看该网站声明的爬取规则。Disallow字段列出的路径表示禁止爬取。User-agent: GPTBot Disallow: / User-agent: ByteSpider Disallow: / User-agent: ToutiaoSpider Disallow: / User-agent: koubeispider Disallow: / User-agent: koubei.com Disallow: / User-agent: amap.com Disallow: / User-agent: * Allow: /note/* Disallow: /events/阅读服务条款:大多数平台的用户协议明确禁止自动化批量抓取数据,违反条款可能导致账号封禁或法律风险。
判断数据用途:即使技术上可以爬取,将数据用于商业目的(销售、竞品分析对外售卖等)在中国《数据安全法》和《反不正当竞争法》框架下可能存在法律风险。
爬虫实操须严格遵守《网络安全法》《数据安全法》《个人信息保护法》《反不正当竞争法》等相关法规。以下行为有明确法律风险,本课程代码不得用于:
- 大规模爬取并转售数据
- 爬取涉及个人隐私的信息(姓名、电话、位置等)
- 对目标服务器发送高频请求,造成服务中断(相当于 DDoS 攻击)
- 突破网站权限限制获取非公开内容
本课程所有代码和示例仅用于教学演示。
爬虫适用的场景判断
在实际工作中,拿到一个数据需求时,可以用以下流程快速判断是否适合用爬虫:
- 数据是否公开可见?(非登录状态下浏览器能否直接看到)
- 数据量是否超过手动整理的合理范围?(通常超过几百条就值得自动化)
- 是否有官方 API (Application Programming Interface,应用程序接口) 可用?(优先使用官方接口,更稳定、更合规)
- robots.txt 和服务条款是否允许?
如果以上四个问题的答案是「是、是、否、是」,爬虫是合适的选择。
13.2 爬虫与文本分析的整体流程
下图展示了从原始网页到分析结论的完整链条,后续我们将通过一些实例来展示各个环节的实操:
Step 1 确定目标
└─ 要获取什么数据?字段是什么?分析目的是什么?
Step 2 分析页面
└─ 数据在 HTML 里还是 API 接口里?
└─ 用浏览器开发者工具定位数据位置
Step 3 编写爬虫(AI 生成代码)
└─ 写提示词 → AI 生成代码 → 运行验证 → 修改提示词
Step 4 数据清洗
└─ 处理缺失值、重复记录、噪音文本、格式不一致
Step 5 词频与词云
└─ 分词(jieba)→ 去停用词 → 统计词频 → 可视化
Step 6 主题分析
└─ LDA 主题模型 → 发现潜在话题结构
Step 7 情感分析
└─ 词典法 / 监督学习 → 判断评论情感极性
Step 8 可视化与决策建议
└─ 图表呈现 → 从数据洞察到经营建议本章覆盖 Step 1 和 Step 2,即「搞清楚要什么」和「知道数据在哪里」。搞清楚这两步,才能写出准确的提示词,提高 AI 生成代码的效率和准确性。
Step 3 至 Step 8 在后续章节逐步实现。
13.3 核心概念与术语
以下概念在后续章节中会反复出现,首次遇到时请回来查阅。主要包括:
- 请求与响应
- 网页结构:HTML
- 接口:API 与 JSON
- 解析、请求头、参数
A. 请求与响应
当你在浏览器里输入一个网址并按下回车,发生的事情是:
- 浏览器向服务器发送一个请求 (request),说「我要这个页面」
- 服务器处理后,向浏览器返回一个响应 (response),内容是网页的原始文本
爬虫模仿的正是这个过程,只不过是由 Python 代码发出请求、接收响应,而不是浏览器。
B. 网页结构:HTML
HTML (HyperText Markup Language,超文本标记语言) 是网页的基本格式。你在浏览器里看到的一切——文字、图片、按钮、表格——都是由 HTML 标签描述的。一个简单的例子:
<div class="review-card">
<span class="stars">4</span>
<p class="review-text">口味不错,服务有点慢。</p>
<span class="date">2024-03-15</span>
</div>这段 HTML 描述了一条评论卡片,包含星级 stars)、文字内容 (review-text) 和日期 (date) 三个字段。爬虫的工作就是找到这些标签,提取其中的文本。
C. 接口:API 与 JSON
很多现代网站不直接把数据写在 HTML 里,而是通过接口 (API) 动态加载。你看到的页面是空壳,数据在浏览器加载后由 JavaScript 从后台接口请求回来。
API 是 Application Programming Interface 的缩写,中文翻译为「应用程序编程接口」。它是一套让你方便、安全、标准地远程获取服务或数据的规则和工具。
这里以「扫码点餐」为例来说明 API 的原理。去餐厅吃饭时,点餐流程大致如下:
- 你在 5 号桌落座后,扫描餐桌上的二维码,手机上会弹出点餐界面(菜单)。
- 你在菜单上勾选:
酸菜鱼,并设置口味:微辣、不要香菜。 - 下单后,手机会自动把你的菜品和要求发送到厨房。
- 厨师收到信息后开始烹饪,最后上菜到你的桌前。
API 的工作原理和这个点餐流程非常相似。采用 API 的术语,上述点餐流程包括如下几个关键概念:
- API 就像餐厅的「点餐系统」,让你不用直接进厨房,只需通过手机菜单(API 接口)就能完成复杂的操作。
- Endpoint(端点):你扫描了 5 号桌上的二维码后进入的点餐页面,就是 API 的 “入口” 或 “网址”。
- Request(请求):你勾选菜品、填写口味、按下 “提交” 按钮,这一系列操作就组成了一个 API 请求,把你的要求传递给餐厅的后厨系统。
- Parameter(参数):你点了哪道菜 (
酸菜鱼)、选择了什么口味(微辣、不要香菜),这些都属于 API 的参数。 - API Key(密钥):类似于账号和密码。就像有些高档餐厅只对会员开放,需要出示会员卡才能点餐,
API Key就像这张会员卡,是一串唯一的字符串,用于证明你的身份和权限。
以上点餐过程的完整请求数据可以采用如下参数方式表示:
request = {"table_number"=5,
"dish"="酸菜鱼",
"spiciness"="微辣",
"no_coriander"=True}这类接口返回的数据通常是 JSON (JavaScript Object Notation) 格式——一种结构清晰、易于程序处理的文本格式。可以看出,JSON 由键值对组成,类似于 Python 的字典 (dict):所有数据都被组织在大括号 {} 里,字段名是字符串,字段值可以是字符串、数字、布尔值,甚至嵌套的列表或字典。
下面是一个带嵌套结构的 JSON 示例,表示某餐厅的评论数据:
{
"restaurant_name": "老字号川菜馆",
"reviews": [
{
"stars": 4,
"text": "口味不错,服务有点慢。",
"date": "2024-03-15"
},
{
"stars": 5,
"text": "强烈推荐!招牌菜必点。",
"date": "2024-03-14"
}
]
}对比 HTML 和 JSON:
| 特征 | HTML | JSON |
|---|---|---|
| 主要用途 | 描述页面结构和样式 | 传输结构化数据 |
| 可读性 | 混杂大量标签,较难直接读取 | 结构清晰,键值对形式 |
| 爬取方式 | CSS 选择器 / XPath 定位标签 | 直接解析为 Python 字典 |
| 常见场景 | 传统网页、静态内容 | 动态加载内容、移动端 App |
D. 解析
解析 (parse) 指从 HTML 或 JSON 文本中提取所需字段的过程。常用工具是 BeautifulSoup 包(处理 HTML)和 Python 内置的 json 模块(处理 JSON)。
E. 请求头
请求头 (headers) 是随请求一起发送的元信息,告诉服务器请求方是「谁」:来自什么设备、浏览器版本、语言偏好等。简言之,这有点类似于我们向他人发送求助邮件时的自我介绍。
爬虫需要设置合适的请求头,尤其是 User-Agent 字段,否则服务器可能拒绝请求或返回异常内容。
真实浏览器的 User-Agent 形如:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36其中,Mozilla/5.0 表示兼容 Mozilla 浏览器,Macintosh; Intel Mac OS X 10_15_7 表示操作系统是 macOS 10.15.7,Chrome/120.0.0.0 表示浏览器版本。
F. 参数
参数 (params) 是附在请求中的查询条件,控制返回哪部分数据。例如:
https://api.example.com/reviews?city=上海&category=川菜&page=2这里 city=上海、category=川菜、page=2 都是参数,告诉服务器「返回上海川菜第 2 页的评论」。
又如,我们可以使用 akshare 包在线获取股票数据,传入的 symbol、start_date、end_date、adjust 等都是参数:
!pip install akshare
import akshare as ak
# 获取平安银行(000001)从 2022-01-01 到 2026-03-12 期间
# 的后复权(hfq)日 K 线数据
stock_df_pingan = ak.stock_zh_a_hist(
symbol="000001",
period="daily",
start_date="20220101",
end_date="20260312",
adjust="hfq"
)
# 显示后复权数据
print(stock_zh_a_hist_hfq_df.tail())13.4 1.4 网页结构分析:使用浏览器开发者工具
理解「数据在哪里」是写好爬虫提示词的前提。浏览器内置的开发者工具 (DevTools) 是完成这项工作的核心工具,完全免费,无需安装任何软件。
下面分别以中山大学 教师名录 页面 (静态页面) 和大众点评 餐厅评论 页面 (动态页面) 为例,介绍如何使用 DevTools。
打开开发者工具
在 Chrome 或 Edge 浏览器中打开 https://lingnan.sysu.edu.cn/Faculty 页面后,有三种方式打开开发者工具:
- 在页面任意位置右键 → 检查 (Inspect)
- 键盘快捷键:Windows 按
F12,Mac 按Command + Option + I - 菜单栏:更多工具 → 开发者工具
三个最常用的面板
开发者工具打开后,顶部是一排标签页,本课程主要使用以下三个:
- Elements(元素)面板:查看和定位 HTML 结构
- Network(网络)面板:监控网络请求,找到数据接口
- Console(控制台)面板:运行 JavaScript 代码,测试数据提取逻辑
A. Elements(元素)面板
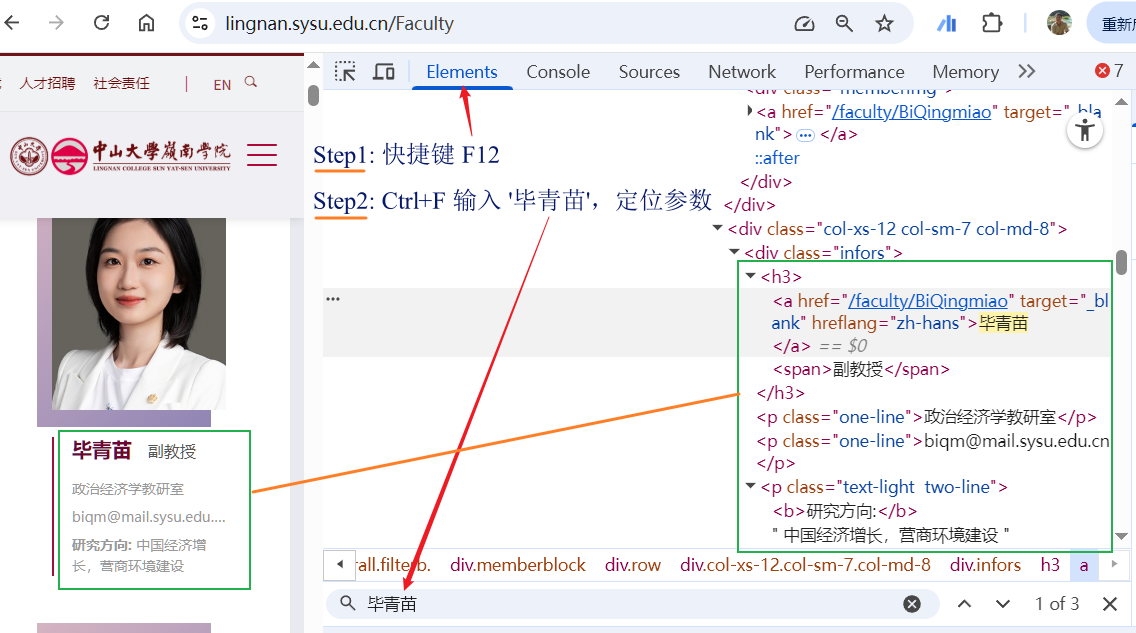
显示当前页面的 HTML 结构。你可以在这里查看任何页面元素对应的 HTML 标签,找到数据所在的标签名和 class 属性。
操作步骤:
- 点击面板左上角的「箭头选择器」图标(Windows/Mac:
Ctrl+Shift+C/Command+Shift+C),此时左侧网页会变成可点击状态 (带有蓝色高亮框) - 在页面上点击你想提取的内容(例如一条评论的文字)
- 右侧 Elements 面板会自动跳转到对应的 HTML 位置
- 记录下标签名(如
<p>、<span>、<div>)和 class 属性值(如class="review-text") - 如需将 HTML 复制给 AI,在目标标签上右键 → Copy → Copy outerHTML (Copy element),即可复制该元素的完整 HTML 代码 (不同的浏览器或不同缩放比例下,显示的结果会略有差异):
<div class="infors">
<h3><a href="/faculty/BiQingmiao" target="_blank" hreflang="zh-hans">毕青苗</a> <span>副教授</span></h3>
<p class="one-line">政治经济学教研室</p>
<p class="one-line">biqm@mail.sysu.edu.cn</p>
<p class="text-light two-line">
<b>研究方向:</b>
中国经济增长,营商环境建设
</p>
</div>说明: 1. 这些代码片段中,<div>、<h3>、<p> 是标签名 (成对出现,包裹不同类型的字段),class="infors"、class="one-line" 是 class 属性。 2. 随后可以把这些 HTML 代码贴给 AI,它会自动解析参数。
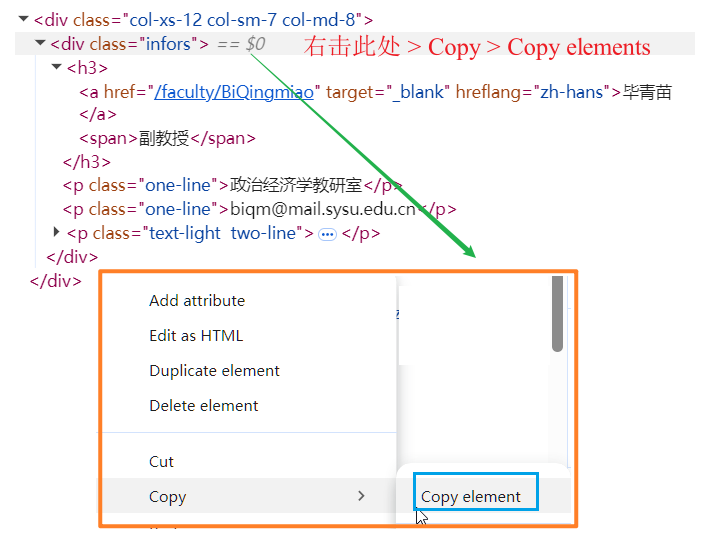
点击页面元素后,Elements 面板高亮的通常是最内层的标签(如 <span>)。如果你想连同周围的父级结构一起复制,可以在 Elements 面板里向上点击几层,找到包含完整信息的父级 <div>,再右键复制。给 AI 提供包含完整字段的外层块,比只复制单个标签更有用。
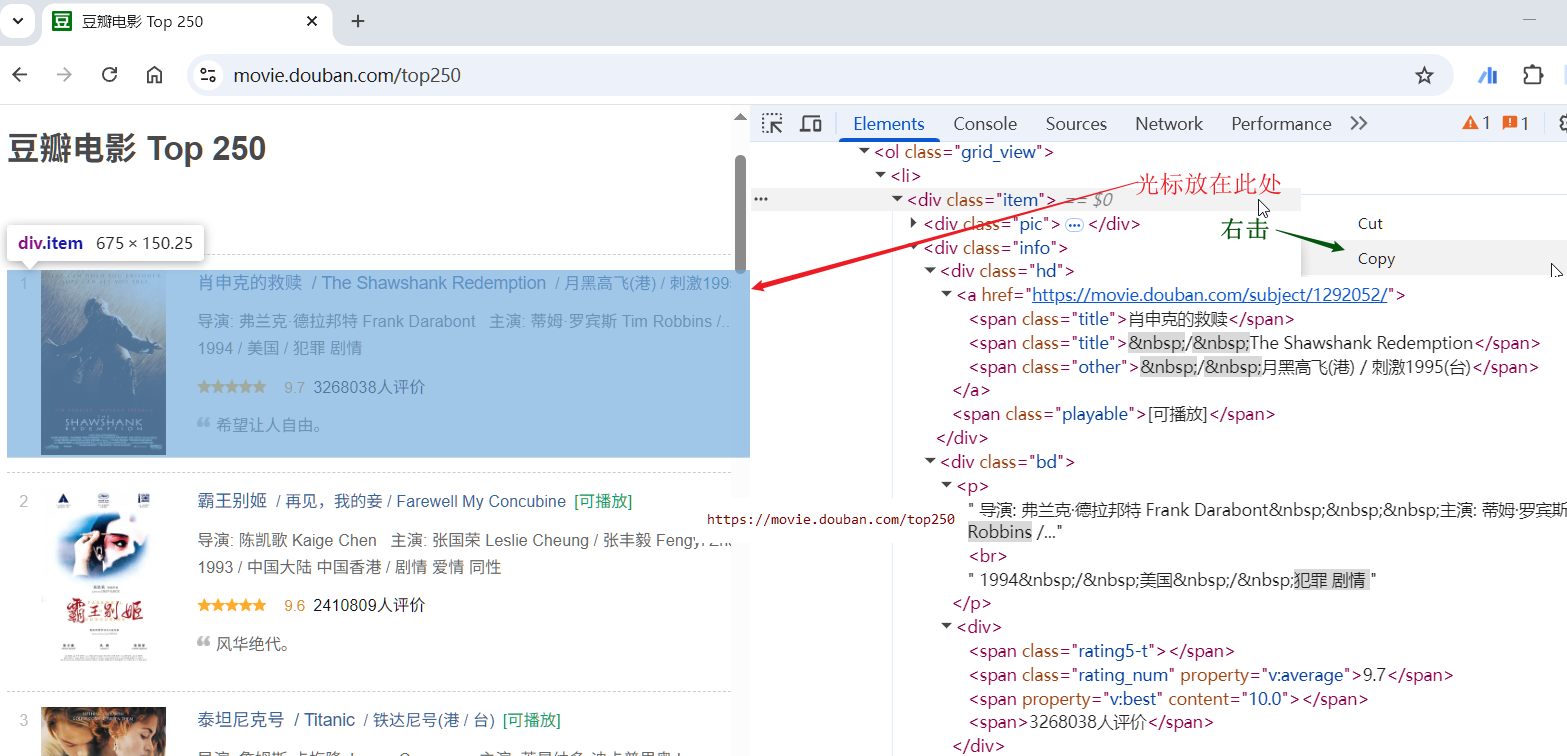
例 2:豆瓣电影 Top 250 评论页面(动态加载数据) 网址:https://movie.douban.com/top250
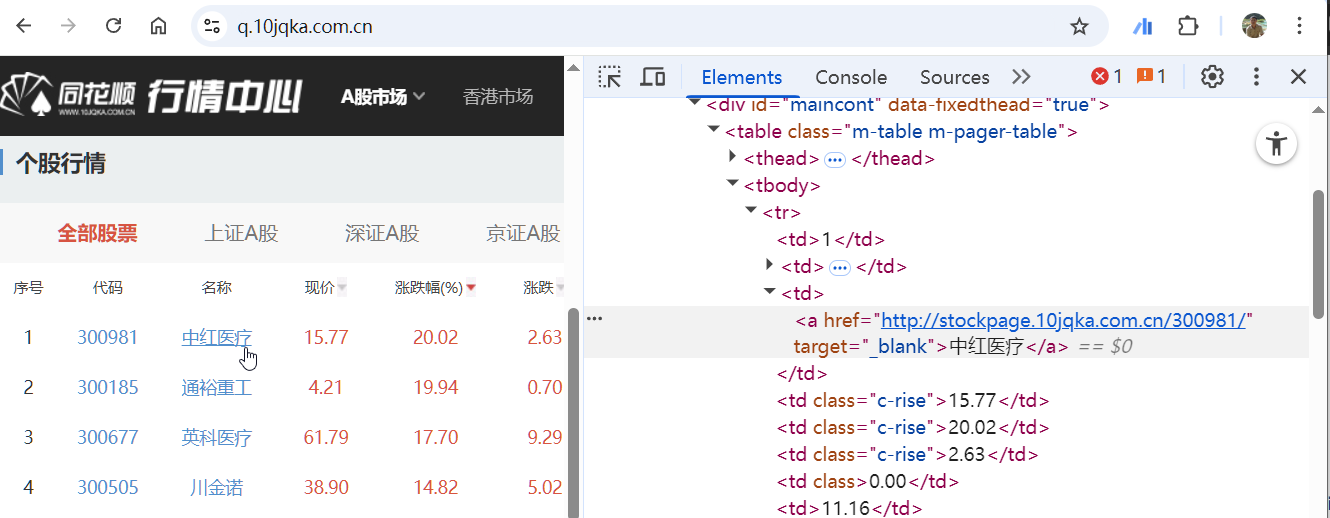
例 3:同花顺行情页(股票行情列表) 网址:https://q.10jqka.com.cn/
B. Network(网络)面板
记录浏览器发出的所有网络请求,包括页面本身和动态加载的 API 接口。这是判断「数据从哪个接口来」的关键工具。
操作步骤:
- 打开网址 https://movie.douban.com/top250
- 打开 Network 面板 → 刷新页面(按
F5或Command + R) - 在左侧请求列表中,点击「Fetch/XHR」标签,过滤出 API 请求
- 逐个点击请求,查看右侧的「Preview」或「Response」标签,找到包含目标数据的那个请求
- 点击「Headers」标签,查看请求的 URL、参数和请求头
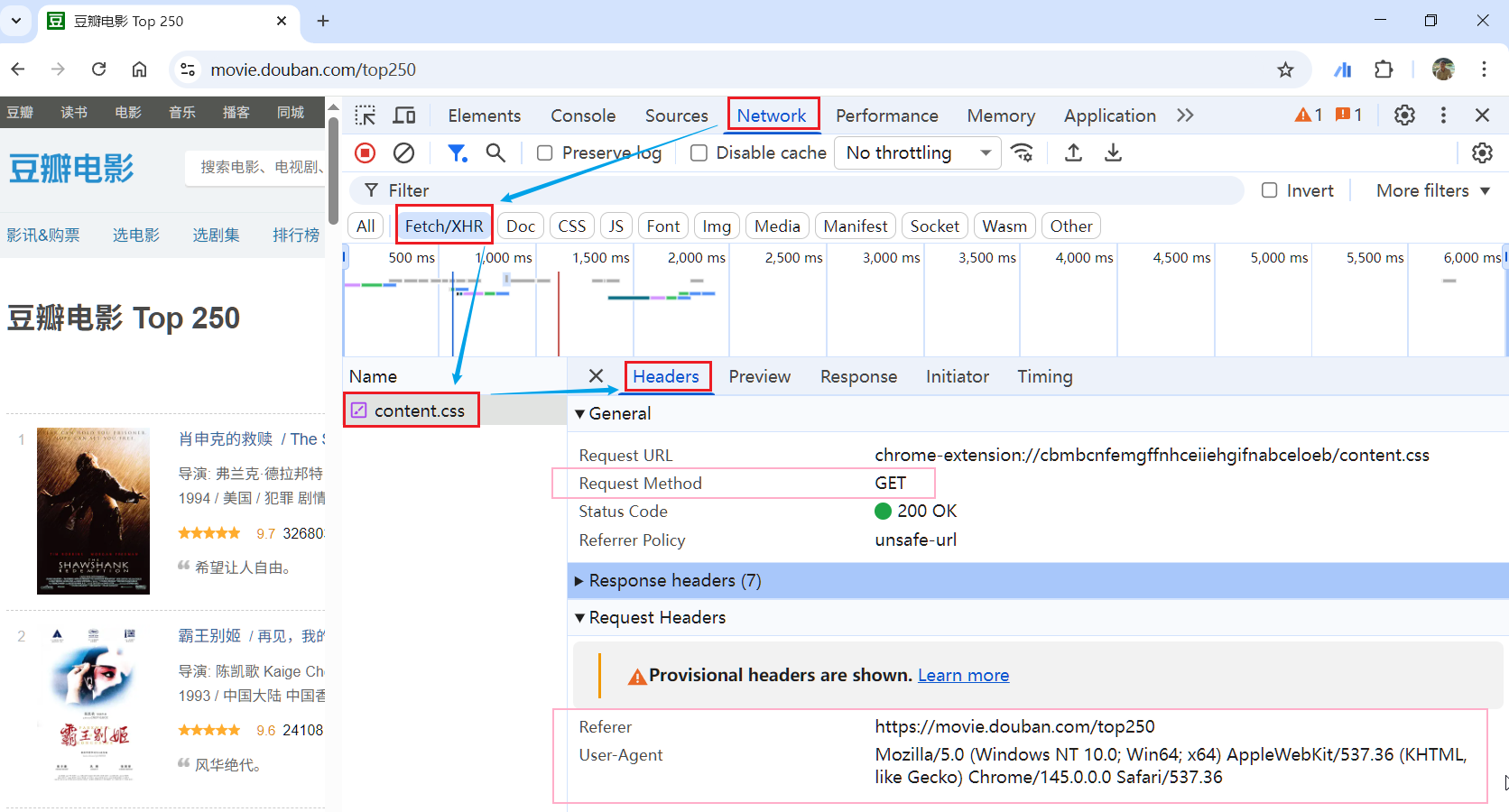
可以复制 Header 信息给 AI (也可以采用上面的截图),帮助它生成带有正确请求头的代码:
referer
https://movie.douban.com/top250
user-agent
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36C. Console(控制台)面板
可以在这里直接运行 JavaScript,用于快速测试数据提取逻辑,但本课程不深入使用。
13.4.1 两种常见的数据来源模式
通过 DevTools 分析,大多数网站的数据来源属于以下两种模式之一:
模式 A:数据直接在 HTML 里
- URL:https://lingnan.sysu.edu.cn/Faculty
- 特征:刷新页面后 Elements 面板中直接能看到数据内容;Network 面板中没有明显的 XHR/Fetch 请求包含数据。
- 提示词关键词:
BeautifulSoup、CSS 选择器、find_all
模式 B:数据通过 API 动态加载
特征:Network 面板中的 XHR/Fetch 请求的 Response 里直接包含 JSON 格式的数据;页面初始 HTML 中数据位置是空的。
提示词关键词:requests.get、response.json()、API 接口
在目标页面按 Ctrl+U(Mac 按 Command+U)查看网页源代码。如果源代码中能直接搜索到你要的数据(如评论文字),则是模式 A;如果搜不到,则是模式 B。
有些页面用 Ctrl+U 查看源码时找不到数据,但在 Elements 面板里 能看到完整的数据节点 —— 例如上交所科创板股票列表:https://star.sse.com.cn/market/stocklist/。
这类页面的数据由 JavaScript 请求回来后渲染成 HTML 写入页面, 不是直接暴露为 JSON 接口。requests 只能拿到渲染前的空壳,BeautifulSoup 解析不到任何数据。
判断方法:Ctrl+U 查不到数据,但 Elements 面板能看到 → 属于这种情形。
爬取方式:需要用 Selenium 或 Playwright 模拟浏览器执行 JavaScript,等页面渲染完成后再提取数据。这类工具超出本课程范围, 遇到时可以告知 AI「页面数据由 JS 动态渲染,请使用 Playwright」。
13.5 数据格式详解:HTML 与 JSON
13.5.1 HTML 小例子
以下是一个简化的大众点评评论列表的 HTML 结构(实际页面更复杂,仅用于说明结构):
<ul class="review-list">
<li class="review-item">
<div class="user-name">匿名用户A</div>
<div class="star-score" data-score="4">四星</div>
<div class="review-content">
环境很好,招牌菜好吃,就是等位时间比较长。
</div>
<div class="review-date">2024-03-15</div>
<div class="useful-count">12</div>
</li>
<li class="review-item">
<div class="user-name">匿名用户B</div>
<div class="star-score" data-score="2">两星</div>
<div class="review-content">
服务态度差,催了两次才上菜,不会再来了。
</div>
<div class="review-date">2024-03-14</div>
<div class="useful-count">25</div>
</li>
</ul>从这段 HTML 中,爬虫需要提取的信息是:
- 评分:
div.star-score的data-score属性,值为4或2 - 评论内容:
div.review-content的文本 - 日期:
div.review-date的文本 - 有用数:
div.useful-count的文本
13.5.2 JSON 小例子
同样的数据,如果通过 API 接口返回,格式如下:
{
"status": "success",
"total": 1283,
"page": 1,
"data": [
{
"user": "匿名用户A",
"score": 4,
"content": "环境很好,招牌菜好吃,就是等位时间比较长。",
"date": "2024-03-15",
"useful": 12
},
{
"user": "匿名用户B",
"score": 2,
"content": "服务态度差,催了两次才上菜,不会再来了。",
"date": "2024-03-14",
"useful": 25
}
]
}JSON 的数据提取比 HTML 简单得多——找到 data 这个键,里面的每个元素就是一条评论记录,直接可以转成 pandas DataFrame。
13.5.3 真实网址示例
以下是几个返回公开 JSON 数据的真实接口,可以在浏览器地址栏直接访问查看:
- GitHub 用户信息(公开 API):
https://api.github.com/users/{username}- 以 Google 为例,其 Github 仓库地址为 github.com/google,用户名为
google,则获取其用户信息的接口是:https://api.github.com/users/google。单击后会看到返回的 JSON 数据。
- 以 Google 为例,其 Github 仓库地址为 github.com/google,用户名为
- 豆瓣电影 Top 250:可在 Network 面板中找到对应接口
在浏览器里打开一个 JSON 接口,你会看到结构化的文本数据,而不是渲染好的网页。这有助于建立直觉:API 返回的就是原始数据,只需要找到正确的键名就能提取。
推荐练习:用浏览器访问上面的 GitHub 接口,识别其中有哪些字段,然后尝试写一段提示词让 AI 用 Python 提取其中的 name、public_repos、followers 字段。
13.6 基于 AI 提示词的爬虫工作流
这是本章最核心的内容。掌握这个工作流,你就掌握了用 AI 辅助完成任何爬虫任务的方法。
13.6.1 完整工作流
1. 明确任务目标
└─ 我要爬什么网站?要哪些字段?分析目的是什么?
2. 分析目标页面
└─ 打开 DevTools,判断数据来源模式(HTML 还是 API)
└─ 记录关键信息:URL、字段名、CSS class / API 参数
::: {.callout-tip}
### 网页观察记录表:写提示词之前先填这张表
很多人直接把网址丢给 AI,说「帮我写个爬虫」。AI 不会替你看网页,它只能给出泛化模板。真正提高代码质量的方式,是先把网页观察结果整理清楚,再写提示词。
建议每次分析一个新网页时,先填写以下记录表:
| 项目 | 内容 |
|------|------|
| 目标网址 | |
| 一条记录对应什么 | (例如:一条评论 / 一本书 / 一则公告) |
| 目标字段清单 | (列出字段名) |
| 是否有分页 | 是 / 否;翻页规律是_____ |
| 是否有详情页 | 是 / 否 |
| 数据来源模式 | HTML(模式 A)/ API 动态加载(模式 B) |
| 关键定位信息 | HTML class 名 / JSON 键路径 |
| 字段识别方式 | 靠 class 直接定位 / 靠内容特征区分(如含 `@` 判断邮箱) |
| 希望输出格式 | CSV / DataFrame / Excel |
| 后续分析目标 | (例如:词频分析 / 情感分析 / 时序分析) |
填完这张表,你就有了写提示词所需的全部原材料。
:::
3. 组织提示词
└─ 按照「关键要素清单」(见 1.7 节)逐项填写
4. 提交给 AI,获取代码
└─ 首选:Claude / ChatGPT / DeepSeek
5. 运行代码,验证输出
└─ 输出是否符合预期字段格式?
└─ 数量是否合理?有无报错?
6. 根据实际情况修改提示词,迭代
└─ 字段名不对 → 回 DevTools 重新确认
└─ 数据缺失 → 补充说明翻页逻辑或 API 参数
└─ 格式不对 → 在提示词里明确输出格式13.6.2 一个完整示例:爬取豆瓣电影 Top 250
步骤 ①:明确任务目标
我想获取豆瓣电影 Top 250 的电影列表,包含:电影名称、评分、评价人数、上映年份。最终保存为 CSV 文件,用于分析评分与年份的关系。
步骤 ②:分析目标页面
访问 https://movie.douban.com/top250,打开 DevTools:
- Elements 面板可直接看到电影数据,判断为模式 A(HTML)
- 每部电影的标题在
<span class="title">标签里 - 评分在
<span class="rating_num">标签里 - 每页 25 部,共 10 页,URL 规律为
?start=0、?start=25、?start=50……
步骤 ③:组织提示词
请帮我用 Python 爬取豆瓣电影 Top 250 的数据。
目标网站:
https://movie.douban.com/top250,共 10 页,翻页规律是 URL 参数start从 0 开始,每次加 25。每部电影需要提取以下字段(HTML 结构我已确认): - 电影名称:
span.title(第一个,去掉斜线后的副标题) - 评分:span.rating_num- 评价人数:span.rating_people,提取数字部分 - 上映年份:p.bd中的第一段文字,用正则提取 4 位年份要求: - 使用 requests + BeautifulSoup - 每次请求间隔 2 到 3 秒(随机) - 设置 User-Agent 请求头,模拟真实浏览器 - 异常处理:某页请求失败时打印错误并跳过,不中断整体程序 - 最终将所有数据保存为
douban_top250.csv,编码 UTF-8 - 代码中加中文注释,便于理解
步骤 ④-⑥:提交、运行、迭代
将上面的提示词提交给 AI,获得代码后:
- 先只运行第一页(把循环限制为 1 次),检查字段是否正确
- 确认无误后,开放全部循环,爬取完整数据
- 用
df.head()和df.info()检查结果
这是爬虫开发中最重要的习惯。全量爬取可能需要几分钟,中途发现字段错了会浪费大量时间。先用单页验证,代价极低。
在提示词里加一句:「先只爬第一页并打印前 5 行结果,确认字段正确后再爬全部页数」,AI 通常会生成带有这个验证步骤的代码。
13.7 写好爬虫提示词的关键要素
一个完整的爬虫提示词应当包含以下八个要素。缺少任何一项,AI 都可能生成不可用或需要大量修改的代码。
13.7.1 要素清单
① 目标网站 (target URL)
- 提供完整 URL,包括具体页面地址
- 如果有翻页,说明翻页规律(URL 参数如何变化)
示例:目标网站是 https://www.example.com/reviews?page=1,翻页时将 page 参数从 1 递增到 20
② 数据字段 (fields)
- 列出所有需要提取的字段名
- 说明每个字段在 HTML/JSON 中的位置(标签名、class 名、JSON 键名)
- 说明是否需要做简单的清洗(如去掉单位、提取数字)
示例:需要提取:评论文字(class="review-text"的 p 标签文本)、星级(class="star"的 span 标签的 data-score 属性)、日期(class="date"的 span 标签文本)
③ 请求方式 (request method)
- 说明是 GET 请求还是 POST 请求(大多数情况是 GET)
- 如果需要登录 Cookie 或特定请求头,说明在 DevTools 里找到的值
示例:使用 GET 请求;需要在 Headers 里设置 Cookie,值为 [从 DevTools 复制的 Cookie 字符串]
④ 数据格式 (data format)
- 明确说明数据在 HTML 里还是 JSON 接口里
- 如果是 JSON,说明目标数据在哪个键下
示例:数据通过 XHR 接口返回 JSON 格式,目标数据在 response.data.list 数组里
⑤ 输出要求 (output)
- 输出格式:CSV、Excel、还是 pandas DataFrame
- 文件名和编码(中文数据指定 UTF-8-sig,避免 Excel 打开乱码)
- 是否需要在控制台打印进度
示例:结果保存为 reviews.csv,编码 UTF-8-sig,同时每爬完一页打印当前进度
⑥ 异常处理 (error handling)
- 网络请求可能超时或失败,说明失败时的处理方式(跳过、重试还是中断)
- 数据字段可能为空,说明如何处理(填 None 还是跳过整条记录)
示例:请求失败时重试最多 3 次,仍失败则跳过当前页并打印错误信息;字段为空时填入空字符串
⑦ 合规要求 (compliance)
- 每次请求的间隔时间(建议 1-3 秒随机,尊重服务器)
- User-Agent 设置(模拟真实浏览器)
示例:每次请求后随机等待 1.5 到 3 秒;User-Agent 设置为 Chrome 浏览器的标准值
⑧ 代码风格 (code style)
- 是否需要中文注释
- 是否需要封装成函数(便于复用)
- 是否需要进度条(适合数据量大的场景)
示例:代码加中文注释,将爬取单页的逻辑封装成函数 fetch_page(url),主程序调用该函数循环爬取
13.7.2 提示词模板
在使用模板之前,先看一个对比。同样是想爬取餐厅评论,两种提示词的质量差距非常大:
帮我写一段 Python 代码,爬取网站评论。
问题:没有说网址、没有说字段、没有说格式、没有说翻页逻辑。AI 只能给出泛化模板,代码几乎无法直接使用。
编写一段合规的 Python 爬虫代码,仅用于课堂实操学习。
- 目标网页:某公开餐饮评论页面,数据为 HTML 格式,每条评论对应一个
div,class="comment-item"- 需要提取的字段:店铺名称(
class="shop-name")、用户评论(class="review-text")、评分(class="star-score"的data-score属性)、评论时间(class="review-date")- 共 5 页,翻页规律是 URL 参数
page从 1 递增到 5- 设置常规请求头,每次请求随机等待 2-3 秒
- 结果保存为 CSV 文件,编码 UTF-8-sig,字段名用中文
- 代码加中文注释;先只爬第一页并打印前 5 行,确认字段正确后再爬全部页
改进点:提供了网址特征、字段定位信息、翻页规律、输出格式、验证步骤,AI 可以据此生成直接可用的代码。
将以上要素组合,形成以下通用模板:
请帮我用 Python 写一个爬虫,完成以下任务:
目标网站:[完整 URL],共 [N] 页,翻页规律是 [说明参数变化]。
采集对象:[每条记录是什么,例如:每条用户评论 / 每本书 / 每则公告]
需要提取的字段: - [字段 1]:位于 [HTML 标签 / JSON 键],需要 [清洗说明,如无则省略] - [字段 2]:位于 [HTML 标签 / JSON 键] - (依此类推)
数据格式:[HTML 页面 / JSON 接口,接口 URL 为 …]
技术要求: - 使用 requests + BeautifulSoup(HTML)/ requests + json(API) - 每次请求随机等待 [X 到 Y] 秒 - User-Agent 设置为真实浏览器值 - 请求失败时 [重试 N 次 / 跳过并记录错误] - 字段缺失时填入 [None / 空字符串]
输出:保存为 [文件名].csv,编码 UTF-8-sig;同时打印每页进度。
后续用途:采集完成后我还要做 [词频分析 / 情感分析 / 时序分析],请保留 [评论正文 / 日期 / 评分] 等相关字段。
代码要求:加中文注释;将单页爬取封装为函数;先只爬第一页并打印前 5 行,确认字段正确。
后续分析目标不同,需要保留的字段也不同:
- 做词频分析:必须保留评论正文字段
- 做情感分析:需要同时保留评论正文和星级评分
- 做时序分析:必须保留日期字段,且格式要规范
- 做店铺间比较:必须保留店铺标识字段
在提示词里加一句「后续我还要做 _____ 分析」,AI 会据此调整字段保留策略,生成的代码对后续工作的适配性更强。
13.8 常见误区与注意事项
误区 1:HTML 里能看到,但爬下来是空的
原因:页面内容由 JavaScript 动态渲染,初始 HTML 是空壳,数据在后续的 API 请求中加载。
解决方法:回到 DevTools 的 Network 面板,过滤 Fetch/XHR,找到实际返回数据的接口,改为直接调用该接口。
误区 2:本地运行正常,改成循环后报错或被封
原因:高频请求触发了网站的反爬机制,服务器返回 403 或 429 状态码(表示禁止访问或请求过频)。
解决方法:
- 增加请求间隔(改为 3-5 秒随机)
- 在提示词里要求 AI 处理状态码异常,状态码非 200 时暂停并重试
- 考虑是否必须爬全量,还是抽样就够
误区 3:代码跑通了,但数据里全是乱码
原因:网页编码与代码指定的编码不一致,或保存 CSV 时没有指定 UTF-8-sig(导致用 Excel 打开时中文乱码)。
解决方法:在提示词里明确要求「保存为 UTF-8-sig 编码的 CSV 文件」。如果网页本身是 GBK 编码,要求 AI 在 requests.get 后加 response.encoding = 'GBK'。
误区 4:第一次提示词就想一步到位
真实情况:爬虫开发几乎不可能一次成功。网页结构随时可能改变,API 参数需要反复试验,字段清洗规则要在看到真实数据后才能确定。
正确姿势:接受迭代是正常状态。第一版提示词先跑通单页,看到真实数据后再调整字段和清洗逻辑,再跑全量。每次迭代都在提示词里描述上一版的问题和期望的修改方向。
误区 5:AI 生成的代码可以直接信任
真实情况:AI 生成的代码可能包含错误,尤其是 CSS 选择器和 API 参数这类依赖真实页面结构的部分,必须对照 DevTools 手动验证。
验证方法:
- 打印中间结果(爬到的原始 HTML 或 JSON),确认数据确实在里面
- 先只提取一条记录并打印,确认字段名和值都正确
- 检查数量是否合理(例如一页应有 20 条评论,实际只有 5 条,说明选择器不完整)
这是 AI 辅助编程中最容易忽略的陷阱。代码能运行,只说明语法上大致没有问题;并不说明抓到的数据就是正确的。
一个真实的反例:某段代码运行后输出了如下表格:
| title | price | stock_status |
|---|---|---|
| £53.74 | In stock | book_1.html |
| £50.10 | In stock | book_2.html |
title 列里出现了价格,stock_status 列里出现了链接——字段全部错位,但程序没有报错。
每次运行 AI 生成的采集代码后,建议检查以下内容:
- 字段是否都在:输出表中是否出现了你要求的所有列
- 字段内容是否合理:标题列中不应出现价格,日期列中不应出现链接
- 是否只抓到一页:如果要求多页,结果只有 20 条,要警惕
- 是否有空值或乱码:文本为空、中文乱码、时间格式混乱是常见问题
- 样本量是否合理:3 页每页 20 条,最终结果只有 10 条,就要检查翻页逻辑
误区 6:同一 class 对应不同字段
原因:部分网页用同一个 class(如 class="info-item")标记多种不同性质的内容(如姓名、职务、邮箱),无法靠 class 名直接区分字段。如果提示词里只写「提取 class="info-item" 的文本」,代码会把所有内容混在一起,或者只取第一个。
解决方法:靠内容特征识别字段(如含 @ 的是邮箱,4 位数字开头的是年份),并在提示词里明确说明识别规则。同时,务必向 AI 提供至少两个结构不同的样例——只有一个样例时,AI 无从得知某些字段可能缺失,生成的代码会在遇到边界情况时出错。
误区 7:爬虫等于数据分析
提醒:爬虫只是获取数据的手段,数据采集完成后还需要大量清洗工作。在实际项目中,数据清洗往往占整个分析工作量的 50% 以上。不要在爬虫阶段花太多时间追求完美,够用就行,重心应放在后续分析。
13.9 本章小结
本章建立了爬虫与文本分析的整体认知框架,为第二章的实战案例做好准备。
核心要点回顾:
- 爬虫是自动化采集公开网页数据的工具,使用前必须确认合规性
- 数据来源有两种模式:HTML 直接渲染(用 BeautifulSoup 提取)和 API 动态加载(直接调用接口获取 JSON)
- 浏览器开发者工具的 Elements 面板和 Network 面板是定位数据位置的核心工具;用右键 → Copy → Copy outerHTML 可将任意元素的 HTML 完整复制给 AI
- 写好爬虫提示词需要提供八个关键要素:目标网站、字段说明、请求方式、数据格式、输出要求、异常处理、合规要求、代码风格;遇到同一 class 对应多种字段时,还需在提示词里说明字段识别规则,并提供至少两个结构不同的 HTML 样例
- 迭代是正常状态,「先跑一页、验证后再跑全量」是最重要的实践习惯
13.10 习题
- 爬取 Github.com 中同时包含
data science+Finance这两个关键词的仓库中,Forks 次数最多的 1= 个仓库的列表,输出到一个 Markdown 文档中。- Tips:你可以从浏览器地址栏中复制网址:https://github.com/search?q=%22data+science%22+AND+python+AND+Finance&type=repositories&s=forks&o=desc
- 要求:先写提示词,然后再由 AI 辅助生成 Python 代码。提交作业时务必提交 AI 对话链接,格式为
[AI 对话记录(URL)