# 安装依赖包
!pip install openpyxl15 爬虫实例 1:岭南学院教师名录整理
从一个网址出发,通过与 AI 的多轮对话,逐步形成规范提示词,最终生成可运行代码。
0. 开始之前
安装依赖
📦 环境准备
pip install requests beautifulsoup4 pandas openpyxlrequests:发送 HTTP 请求,获取网页内容beautifulsoup4:解析 HTML,提取目标字段pandas:整理数据,输出 Excelopenpyxl:pandas输出.xlsx格式的底层依赖
设定 AI 工作模式
大多数 AI 的默认行为是「收到任务 → 立即给出完整答案」。对于爬虫任务,这意味着:你说「帮我写爬虫」,它会直接生成一段可能完全不符合需求的代码,而不是先问清楚你要什么。
在发出第一条消息之前,先把以下角色设定提示词完整复制,单独发给 AI(ChatGPT / DeepSeek / 豆包均适用),收到「明白」后再开始对话:
📋 角色设定提示词
接下来我们要合作完成一个网页爬虫任务。请你扮演一位爬虫开发引导者,遵守以下规则:
- 不要直接生成代码,除非我明确说「请生成代码」
- 每次回复只问我一到两个最关键的问题,等我回答后再继续
- 引导我依次提供:目标网址、需要的字段、数据用途、HTML 结构(需我去 DevTools 查)、是否有翻页、输出格式——但不要一次全问
- 信息足够后,先把收集到的内容整理成结构化提示词给我确认,我确认后再生成代码
- 如果我的信息有歧义或可能导致代码出错,请追问,不要自行假设
收到后请回复「明白,请告诉我你的爬虫任务」。
1. 与 AI 的对话过程
下面是一个零基础学生发送角色设定后,与 AI 完成这项任务的完整对话记录。
阅读方式:通读全部六轮对话,理解每轮在解决什么问题。操作步骤(如何使用 DevTools)集中在第 2 节,读完对话再去操作。
🧑 学生·第 1 轮
我想爬取这个网页的信息:https://lingnan.sysu.edu.cn/Faculty,帮我写一个 Python 爬虫。(附上截图)
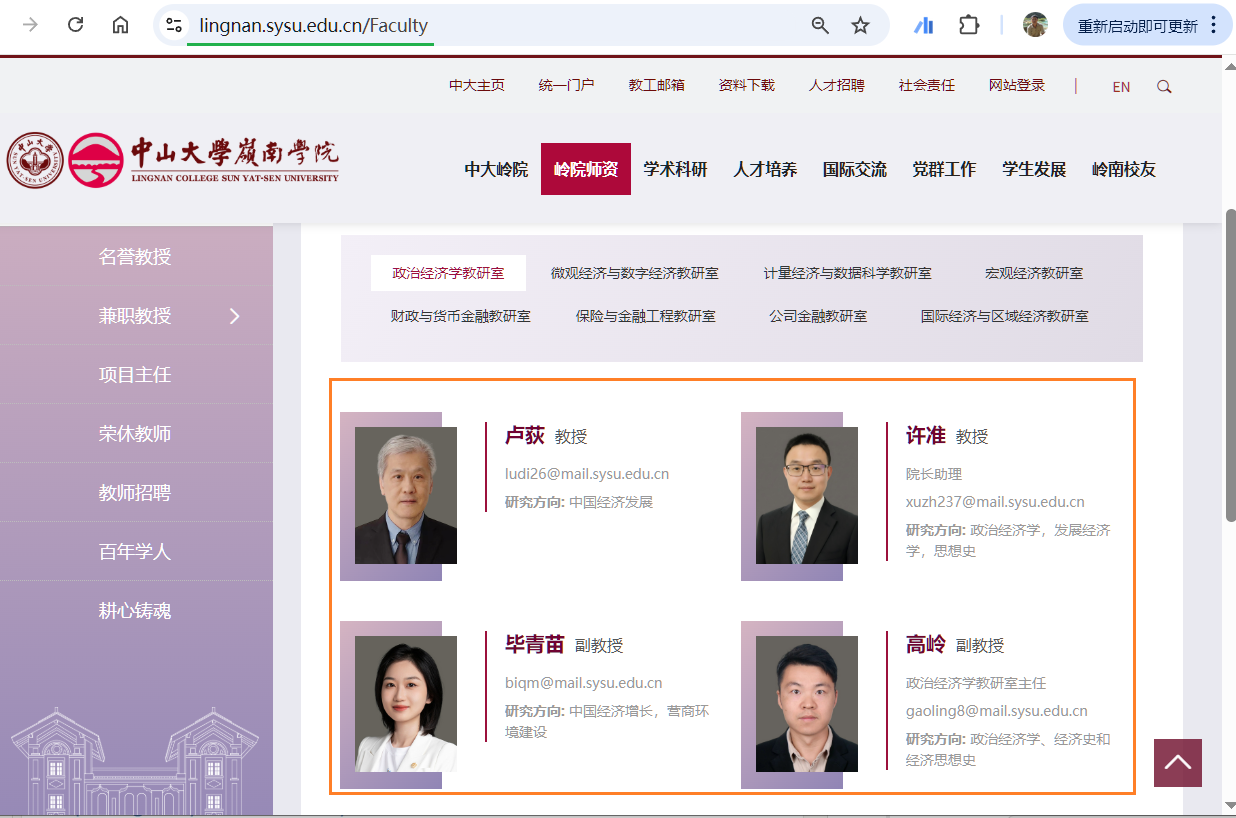
💡 本轮要点:AI 没有直接写代码,而是先问「要什么」和「做什么用」——对应第一章提示词八要素中的要素②(数据字段)和要素⑤(输出要求)。
💡 本轮要点:AI 需要 HTML 结构才能写出正确的选择器,但它看不到网页——必须让你去 DevTools 里取。这正是第一章 1.4 节介绍 DevTools 的实战应用。
💡 本轮要点:AI 从截图中发现「院长助理」,主动要求第二个样例——因为只有一个样例时,无法发现字段可能缺失的情况(对应第一章误区⑥)。
💡 本轮要点:AI 主动建议增加 Markdown 输出(要素⑤),并追问翻页问题(要素①)——不确认翻页逻辑,代码可能只抓到当前筛选下的教师,而非全部名录。
💡 本轮要点:AI 在生成代码前先整理提示词、等待确认——这是本章最重要的工作习惯。对话中散落的信息在这一步汇聚成标准格式,也让你看清「提示词是怎么从对话里生长出来的」。
2. DevTools 操作指引
本节对应第 3 轮对话中 AI 要求「复制 HTML」的操作步骤。如果你已经熟悉 DevTools,可以跳过。
DevTools 的基本用法见第一章 1.4 节。这里只补充一个新动作:如何复制单个元素的完整 HTML。
第一步:打开 DevTools,定位目标元素
- Windows:
F12或Ctrl+Shift+C(直接进入元素选择模式) - Mac:
Command+Option+I或Command+Shift+C
用箭头选择器点击页面上任意一位教师的姓名,Elements 面板会自动高亮对应的 <a> 标签。
📷 截图插入点 A:在
lingnan.sysu.edu.cn/Faculty页面,用箭头选择器点击「卢荻」后,Elements 面板高亮<a>标签、周围可见<div class="infors">完整结构的截图。
第二步:向上选取外层 <div>
Elements 面板高亮的是最内层的 <a> 标签。在面板里点击上方的 <div class="infors">,选中包含该教师全部信息的外层块。
📷 截图插入点 B:在 Elements 面板中,点击
<a>标签上方的<div class="infors">,整个教师信息块被蓝色高亮的截图。
第三步:复制 outerHTML
在 <div class="infors"> 上右键 → Copy → Copy outerHTML,即可复制该教师的完整 HTML 代码,直接粘贴给 AI。
📷 截图插入点 C:右键菜单展开「Copy」子菜单,「Copy outerHTML」选项高亮的截图。
💡 为什么要复制外层
<div>,而不是直接复制 <a> 标签?
<a> 标签只包含姓名和链接,AI 看不到邮箱、研究方向等其他字段。复制包含完整信息的外层块,AI 才能分析字段之间的结构关系,写出正确的解析逻辑。
3. 代码
import requests
from bs4 import BeautifulSoup
import pandas as pd
# ── 请求头:模拟真实浏览器,避免被服务器拒绝 ──
HEADERS = {
'User-Agent': (
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/120.0.0.0 Safari/537.36'
)
}
BASE_URL = 'https://lingnan.sysu.edu.cn'
LIST_URL = f'{BASE_URL}/Faculty'
def make_abs_url(href: str) -> str:
"""
将相对链接转为绝对链接。
"""
if not href:
return ''
href = href.strip()
if href.startswith('http://') or href.startswith('https://'):
return href
if href.startswith('/'):
return BASE_URL + href
return BASE_URL + '/' + href
def parse_faculty(card) -> dict:
"""
解析单个教师信息块,返回标准字段字典。
字段缺失时填空字符串。
"""
result = {
'姓名': '',
'职称': '',
'教研室': '',
'职务': '',
'研究方向': '',
'电子邮箱': '',
'个人主页链接': ''
}
# ── 1. 姓名 + 个人主页链接 + 职称 ──
h3 = card.find('h3')
if h3:
a_tag = h3.find('a')
if a_tag:
result['姓名'] = a_tag.get_text(strip=True)
href = a_tag.get('href', '')
result['个人主页链接'] = make_abs_url(href)
# 有些页面把职称放在 h3 内的 span 里
span = h3.find('span')
if span:
result['职称'] = span.get_text(strip=True)
else:
# 如果没有 span,则尝试从 h3 的纯文本中剥离姓名,提取剩余部分作为职称
h3_text = h3.get_text(' ', strip=True)
if result['姓名'] and h3_text.startswith(result['姓名']):
title = h3_text.replace(result['姓名'], '', 1).strip()
result['职称'] = title
# ── 2. 处理 p 标签:教研室 / 职务 / 邮箱 ──
# 原网页中通常:
# 第一个 one-line 是教研室
# 含 @ 的是邮箱
# 其他 one-line 往往是职务
one_lines = card.find_all('p', class_='one-line')
for i, p in enumerate(one_lines):
text = p.get_text(' ', strip=True)
if not text:
continue
if i == 0 and not result['教研室']:
result['教研室'] = text
elif '@' in text:
result['电子邮箱'] = text
else:
# 可能存在多个非邮箱 one-line,合并为“职务”
if result['职务']:
result['职务'] += ';' + text
else:
result['职务'] = text
# ── 3. 研究方向 ──
two_line = card.find('p', class_='two-line')
if two_line:
raw = two_line.get_text(' ', strip=True)
raw = raw.replace('研究方向:', '').replace('研究方向:', '').strip()
result['研究方向'] = raw
return result
def deduplicate_faculty(records: list) -> list:
"""
对教师记录去重。
优先使用“个人主页链接”作为唯一标识;
若主页链接为空,则退化为“姓名 + 邮箱”。
"""
seen = set()
clean_records = []
for row in records:
# 优先使用主页链接去重
if row['个人主页链接']:
key = ('url', row['个人主页链接'])
else:
key = ('fallback', row['姓名'], row['电子邮箱'])
if key not in seen:
seen.add(key)
clean_records.append(row)
return clean_records
def main():
# ── Step 1:请求页面 ──
print(f'正在请求:{LIST_URL}')
resp = requests.get(LIST_URL, headers=HEADERS, timeout=20)
resp.raise_for_status()
resp.encoding = 'utf-8'
# ── Step 2:解析 HTML ──
soup = BeautifulSoup(resp.text, 'html.parser')
# 仍然先按原有 class 抓取,但随后必须去重
cards = soup.find_all('div', class_='infors')
print(f'原始抓取到 {len(cards)} 个信息块')
# ── Step 3:解析全部记录 ──
all_faculty_raw = []
for card in cards:
info = parse_faculty(card)
# 过滤明显无效记录:
# 至少要有姓名;同时主页链接中不应是列表页本身
if not info['姓名']:
continue
if info['个人主页链接'].rstrip('/') == LIST_URL.rstrip('/'):
continue
all_faculty_raw.append(info)
print(f'解析后得到 {len(all_faculty_raw)} 条原始教师记录')
# ── Step 4:去重 ──
all_faculty = deduplicate_faculty(all_faculty_raw)
print(f'去重后保留 {len(all_faculty)} 位教师')
# ── Step 5:预览前 5 条 ──
print('\n【前 5 条预览】')
for row in all_faculty[:5]:
for k, v in row.items():
print(f' {k}:{v}')
print()
# ── Step 6:转为 DataFrame ──
df = pd.DataFrame(all_faculty)
# 可选:按姓名排序,便于查阅
df = df.sort_values(by='姓名', kind='stable').reset_index(drop=True)
# ── Step 7:输出 Excel;若环境缺 openpyxl,则退回 CSV ──
try:
df.to_excel('lingnan_faculty.xlsx', index=False)
print(f'✅ Excel 已保存:lingnan_faculty.xlsx(共 {len(df)} 条)')
except ModuleNotFoundError:
print('⚠️ 未安装 openpyxl,无法写入 xlsx,改为输出 CSV')
df.to_csv('lingnan_faculty.csv', index=False, encoding='utf-8-sig')
print(f'✅ CSV 已保存:lingnan_faculty.csv(共 {len(df)} 条)')
# ── Step 8:输出 Markdown ──
md_lines = ['# 中山大学岭南学院教师名录', '']
for row in all_faculty:
title_line = f"- **{row['姓名']}**"
if row['职称']:
title_line += f"|{row['职称']}"
md_lines.append(title_line)
if row['教研室']:
md_lines.append(f" - 教研室:{row['教研室']}")
if row['职务']:
md_lines.append(f" - 职务:{row['职务']}")
if row['研究方向']:
md_lines.append(f" - 研究方向:{row['研究方向']}")
if row['电子邮箱']:
md_lines.append(f" - 邮箱:<{row['电子邮箱']}>")
if row['个人主页链接']:
md_lines.append(f" - 主页:<{row['个人主页链接']}>")
md_lines.append('')
with open('lingnan_faculty.md', 'w', encoding='utf-8') as f:
f.write('\n'.join(md_lines))
print('✅ Markdown 已保存:lingnan_faculty.md')
if __name__ == '__main__':
main()正在请求:https://lingnan.sysu.edu.cn/Faculty
原始抓取到 249 个信息块
解析后得到 249 条原始教师记录
去重后保留 83 位教师
【前 5 条预览】
姓名:毕青苗
职称:副教授
教研室:政治经济学教研室
职务:
研究方向:中国经济增长,营商环境建设
电子邮箱:biqm@mail.sysu.edu.cn
个人主页链接:https://lingnan.sysu.edu.cn/faculty/BiQingmiao
姓名:才国伟
职称:教授
教研室:国际经济与区域经济教研室
职务:
研究方向:经济增长与发展、国际经济与政策、 数字经济与政策等
电子邮箱:caiguow@mail.sysu.edu.cn
个人主页链接:https://lingnan.sysu.edu.cn/faculty/CaiGuowei
姓名:蔡荣鑫
职称:副教授
教研室:公司金融教研室
职务:
研究方向:企业并购、私募股权与风险投资、经济增长与贫困问题
电子邮箱:cairx@mail.sysu.edu.cn
个人主页链接:https://lingnan.sysu.edu.cn/faculty/CaiRongxin
姓名:陈川
职称:副教授
教研室:计量经济与数据科学教研室
职务:
研究方向:联邦学习、机器学习鲁棒性、LLM可靠性、图机器学习、社交网络分析
电子邮箱:chenchuan@mail.sysu.edu.cn
个人主页链接:https://lingnan.sysu.edu.cn/faculty/ChenChuan
姓名:陈刚
职称:教授
教研室:国际经济与区域经济教研室
职务:
研究方向:物流工程、运营管理、数字经济
电子邮箱:lnscheng@mail.sysu.edu.cn
个人主页链接:https://lingnan.sysu.edu.cn/faculty/ChenGang
✅ Excel 已保存:lingnan_faculty.xlsx(共 83 条)
✅ Markdown 已保存:lingnan_faculty.md
提示词
AI 生成的原始代码一共输出了 249 条教师记录,我反馈了这个信息后,AI 修正了代码,得到了正确的结果。
4. 验证:看到什么才算正确
代码运行后,Step 3 会打印前 3 条预览。对照以下标准判断是否继续:
| 检查项 | 期望结果 | 若不符合 |
|---|---|---|
| 姓名列 | 全为中文姓名 | 若出现邮箱或职称,字段严重错位,检查 parse_faculty 逻辑 |
| 邮箱列 | 含 @,格式如 xxx@mail.sysu.edu.cn |
若为空或出现姓名,@ 识别逻辑有误 |
| 教师总数 | 几十至一百多条 | 若只有个位数,find_all('div', class_='infors') 的 class 名可能写错 |
| 职务列 | 少数教师有值,多数为空 | 若全部为空,检查职务识别逻辑;全部有值则可能把教研室误判为职务 |
💡 「职务为空」是正常现象
大多数教师没有行政职务,职务 列为空不是错误。检查的目的是区分「正常缺失」(无职务)和「解析错位」(职务被错误地识别为邮箱,或邮箱被丢失)。
5. 如果结果不对:发起调试对话
字段出错时,不要从头重写提示词,而是把具体错误现象告诉 AI。有效的调试消息包含三件事:
① 错误现象(哪列出了什么问题)
② 已做的验证(你确认了什么)
③ 中间结果(打印出的原始数据或 HTML)示例:
代码跑通了,但「职务」列全部为空。我去页面确认过,许准的卡片里确实有「院长助理」。
我打印了许准对应的
one_lines内容:政治经济学教研室 院长助理 xuzh237@mail.sysu.edu.cn三行都在,但职务列还是空的。
这三件事让 AI 能精准定位问题,而不是重写整段代码。信息越具体,修复越快。
6. 复盘
六轮对话,每轮解决了什么:
| 轮次 | 学生提供了什么 | AI 追问了什么 | 对应要素 |
|---|---|---|---|
| 第 1 轮 | 网址 + 截图 | 要哪些字段?做什么用? | ②⑤ |
| 第 2 轮 | 字段清单 + 用途 | 去 DevTools 取 HTML | ④ |
| 第 3 轮 | 一段 HTML | 发现结构不一致,要第二段 | ② |
| 第 4 轮 | 第二段 HTML | 建议加 Markdown;追问翻页 | ①⑤ |
| 第 5 轮 | 确认无翻页 | 整理提示词,等待确认 | — |
| 第 6 轮 | 确认提示词 | 生成代码 | — |
💡 规律:AI 追问 = 填写提示词模板的空格
对比这次对话和第一章 1.7 节的提示词通用模板,你会发现:AI 每次追问,恰好对应模板里缺失的一个要素。
理解这个规律后,下次可以反过来操作:先自己对照模板把空格填好,再发给 AI,减少来回追问的轮数,第一次就拿到更可用的代码。
课堂讨论
第 3 轮中,如果学生只贴了卢荻的 HTML(没有许准的),AI 生成的代码会在哪里出错?出错的现象是什么?
调试消息的三要素(错误现象、已做验证、中间结果)中,哪一项最容易被忽略?忽略它会带来什么后果?
本例的页面只需请求一次,不需要设置请求间隔。如果改为爬取每位教师的详情页,提示词里需要新增哪些内容?
浏览输出结果
lingnan_faculty.md时,发现曾燕老师的信息显示格式有误。请分析原因,并撰写提示词,让 AI 优化代码。- **曾燕**|教授 - 教研室:保险与金融工程教研室 - 研究方向:数字(普惠)金融:创新、风险与监管 数字经济(发展趋势、社会效应、风险与安全) 数字保险:创新、风险与监管 平台经济:定价、风险管理、监管 金融工程:定价、资产配置 风险管理:风险测度、风险传染、风险管理策略 保险精算:保险公司投资、分红与再保险策略等 - 邮箱:<zengy36@mail.sysu.edu.cn> - 主页:<https://lingnan.sysu.edu.cn/faculty/ZengYan>