11 数据管理:格式、存储与工作流
11.1 本章导读
你即将进入的工作环境,和课堂上的数据练习有一个根本性的差别。
课堂上,老师给你一个整洁的 CSV 文件,几百行,列名清晰,直接 pd.read_csv() 就能用。但在银行、券商或研究机构,你面对的可能是这样的局面:
师兄发来一个压缩包,解压后是 6 个子文件夹,47 个 CSV 文件,总计 3.2 GB。你打开其中一个需要等 20 秒;想把所有文件合并,内存溢出,Jupyter 崩溃;终于合并成功了,发现 ticker 列里「000001」变成了数字 1,前导零丢失;花了三天清洗完数据,同事说他用的是另一个版本,两个人的分析结果对不上……
这不是极端情况,这是真实战场的日常。
本章的目标不是让你现在就掌握所有工具,而是让你建立正确的数据管理理念,知道专业人士是怎么工作的,并且在需要的时候能够快速上手。
本章能力层级说明:
| 层级 | 你能做什么 | 对应工具 |
|---|---|---|
| 入门 | 读写 CSV,用 pandas 完成基本分析 | CSV + pandas |
| 进阶 | 处理大文件,跨表关联查询 | Parquet + SQLite |
| 专业 | 跨文件 SQL,分区存储,团队协作 | DuckDB + 分区 Parquet |
| 业界 | 分布式计算,数据湖 | Spark + Delta Lake |
本课程帮你从「入门」升到「进阶」,同时让你看懂「专业」和「业界」层级在做什么。
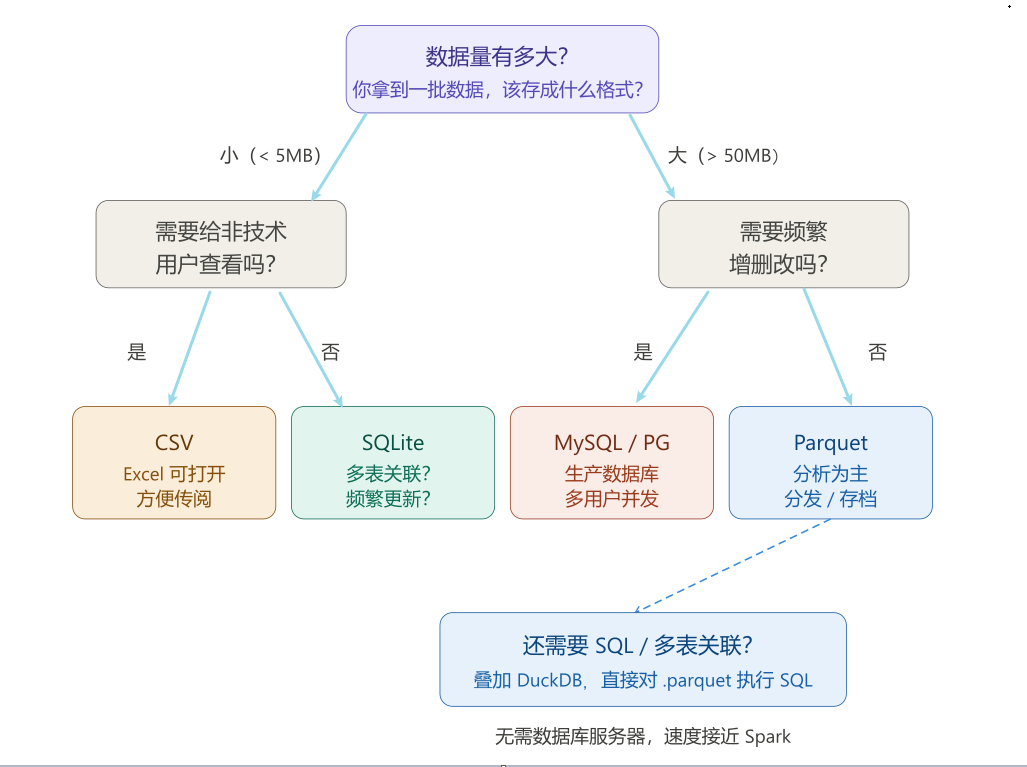
11.2 核心理念:数据格式是一种契约
在开始介绍具体工具之前,需要先建立一个贯穿本章的核心概念。
选择数据格式不只是一个技术决定,更是一种沟通契约。 它决定了:你的数据能被谁读、读多快、读多准;接收方是否需要猜测字段的类型;团队成员拿到文件后能不能直接使用。
CSV 是一种「人类可读」的格式,任何人用 Excel 打开都能看懂,但它不携带任何类型信息——date 列可能被读成字符串,ticker「000001」可能被读成整数 1,空值可能是空字符串、N/A、--、#N/A 中的任何一种,每次读入都需要手动修复。
Parquet 是一种「机器高效」的格式,它把数据类型、压缩方式、字段说明都打包在文件里,接收方读入时不需要猜测,类型自动还原。这就是「契约」的含义:格式本身承诺了数据的结构。
一个简单的判断框架:
- 数据用于与人交流(发给导师、领导、客户)→ 给 CSV 或 Excel
- 数据用于计算和分析(自己跑模型、存中间结果)→ 存 Parquet
- 数据需要多表关联(行情 × 财报 × 宏观)→ 用 SQLite 或 DuckDB
11.3 文件命名与目录规范
在所有数据管理习惯中,这一条的投入产出比最高,也是最容易被忽视的。
11.3.1 命名的坏例子与好例子
以下场景在研究生论文写作和实习中极为常见:
# 坏的命名(真实案例)
最终版.csv
最终版2.csv
最终版_修改.csv
最终版_真的最终.csv
老师改过的.xlsx
用这个!!.csv
data_20240115(1).csv这些文件名的问题是:无法排序、无法知道时间范围、无法知道谁改过、无法知道哪个是最新版。
好的命名遵循一个简单原则:主题_时间范围_版本.扩展名
# 好的命名
fin_ratios_2010_2023_v1.csv # 财务比率,2010-2023年,第1版
stock_daily_000001_20230101.parquet # 000001日线,2023年1月1日起
macro_cpi_ppi_2000_2024.parquet # 宏观数据,CPI和PPI,2000-2024命名规则:
- 用下划线
_分隔词组,不用空格(空格在命令行中会引发问题) - 日期用
YYYYMMDD或YYYY_MM格式,可以按字母顺序排序 - 版本号用
v1、v2而不是「最终」、「修改」 - 全部小写英文,避免中文文件名(在不同操作系统间传输时容易乱码)
11.3.2 目录结构
一个研究项目的推荐目录结构如下:
project_momentum_factor/ # 项目根目录,名称描述研究主题
│
├── data/
│ ├── raw/ # 原始数据:只读,永远不修改
│ │ ├── wind_stock_daily_2023.csv
│ │ └── wind_fin_ratios_2023.csv
│ ├── processed/ # 清洗后的数据
│ │ ├── stock_daily_clean.parquet
│ │ └── fin_ratios_clean.parquet
│ └── outputs/ # 分析结果和因子数据
│ └── factor_momentum.parquet
│
├── notebooks/
│ ├── 01_data_cleaning.ipynb # 数字前缀保证执行顺序
│ ├── 02_factor_construction.ipynb
│ └── 03_regression_analysis.ipynb
│
├── scripts/ # 可复用的函数和工具
│ └── data_utils.py
│
└── README.md # 数据来源、字段说明、更新日期最重要的一条规则:data/raw/ 目录下的文件只读,永远不修改。 所有清洗和处理都在代码中完成,原始文件保持原样。这样任何时候都可以从原始数据重新生成所有结果。
11.3.3 README.md 的最简模板
每个数据项目都应该有一个 README 文件,回答三个问题:这份数据从哪来?经过了什么处理?最后更新是什么时候?
# 动量因子研究项目
## 数据来源
- 股票日线数据:Wind 金融终端,账号 research01
- 财务比率数据:Wind 财务数据库
## 数据范围
- 时间:2010-01-01 至 2023-12-31
- 标的:A 股全市场(含退市,已标记)
## 处理说明
- 已剔除 ST 股票和上市不足 12 个月的股票
- ticker 列统一为 6 位字符串(补前导零)
- 缺失值来源:Wind 原始数据中的 "--",已替换为 NaN
## 更新记录
- 2024-01-15:初始版本,张三
- 2024-02-03:新增 2023Q4 财务数据,李四我正在开始一个金融数据分析项目,研究主题是 [你的研究主题,例如:A 股动量因子]。
数据来源包括:
- [数据1,例如:Wind 股票日线数据]
- [数据2,例如:Wind 财务比率数据]
请帮我:
- 生成一个适合这个项目的目录结构(包含 data/raw、data/processed、notebooks 等)
- 给出 3-5 条适合这类数据的文件命名示例
- 生成一个 README.md 模板,包含数据来源、处理说明、更新记录三个部分
要求:目录结构用代码块展示,文件名全部小写英文加下划线。
11.4 Parquet:列式存储与数据契约
11.4.1 为什么不能只用 CSV
先用一个小例子感受问题所在。假设你有一份上市公司财务数据,100 万行,6 列:
import pandas as pd
import numpy as np
import time
import os
# 生成模拟数据(100万行财务数据)
np.random.seed(42)
n = 1_000_000
df = pd.DataFrame({
"date": pd.date_range("2010-01-01", periods=n, freq="D").astype(str),
"ticker": [str(i).zfill(6) for i in np.random.randint(1, 5000, n)],
"roe": np.random.uniform(-0.2, 0.3, n).round(4),
"pe_ratio": np.random.uniform(5, 80, n).round(2),
"revenue": np.random.uniform(1e8, 1e11, n).round(0),
"industry": np.random.choice(["银行", "医药", "地产", "消费", "科技"], n),
})
# 保存为 CSV
df.to_csv("fin_ratios.csv", index=False)
# 保存为 Parquet
df.to_parquet("fin_ratios.parquet", index=False)
# 比较文件大小
csv_mb = os.path.getsize("fin_ratios.csv") / 1024**2
parquet_mb = os.path.getsize("fin_ratios.parquet") / 1024**2
print(f"CSV 文件: {csv_mb:.1f} MB")
print(f"Parquet 文件:{parquet_mb:.1f} MB")
print(f"压缩比: {csv_mb / parquet_mb:.1f}x")典型输出:
CSV 文件: 98.3 MB
Parquet 文件:18.7 MB
压缩比: 5.3x文件小了 5 倍,但这还不是最重要的差异。真正的差异在读取速度:
# 只需要 roe 列做计算,对比两种方式的速度
# CSV:必须读取全部列才能得到 roe
t0 = time.time()
roe_csv = pd.read_csv("fin_ratios.csv")["roe"]
print(f"CSV 读取 roe 列:{time.time() - t0:.2f} 秒")
# Parquet:只读取 roe 列,其他列的数据不会被加载
t0 = time.time()
roe_pq = pd.read_parquet("fin_ratios.parquet", columns=["roe"])
print(f"Parquet 读取 roe 列:{time.time() - t0:.2f} 秒")典型输出:
CSV 读取 roe 列:3.21 秒
Parquet 读取 roe 列:0.09 秒速度快了约 35 倍。差异来自存储方式的根本不同。
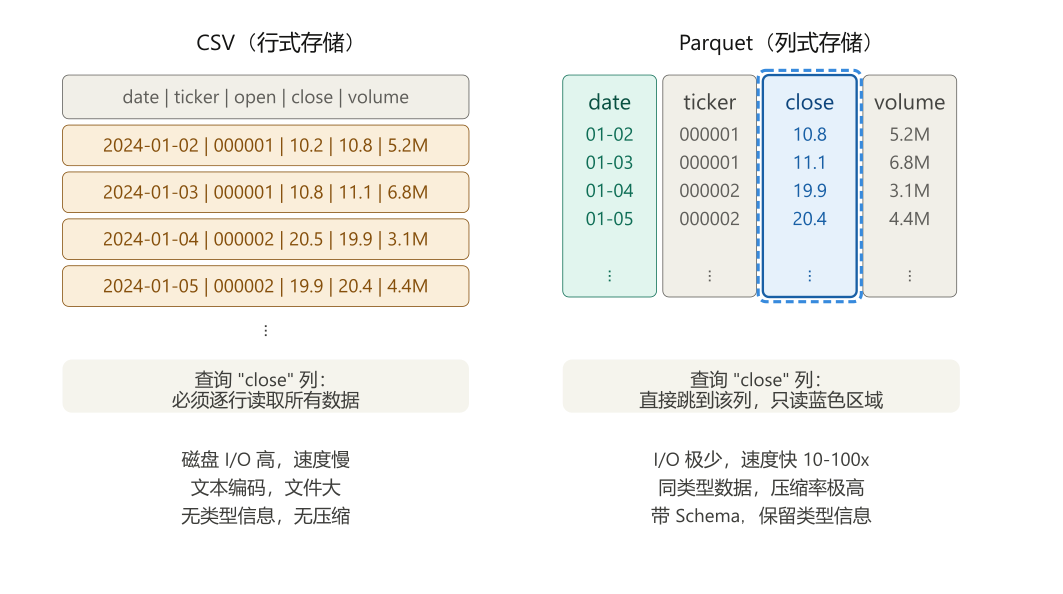
11.4.2 列式存储的直觉
CSV 是「行优先」存储:每一行的所有字段连续存放。要取出 roe 列,必须把每一行都读进来,再丢掉其他列。
Parquet 是「列优先」存储:同一列的所有数据紧挨着存放。要取出 roe 列,直接跳到那一列的位置读取,其他列完全不碰。
此外,Parquet 对每一列独立压缩,效率极高:
industry列只有 5 个值(银行、医药、地产……),用字典编码存储,100 万行只需要 5 个字符串 + 100 万个索引号date列是有序的日期,用差值编码存储,每个日期只记录与前一个的差值roe列是浮点数,用通用压缩算法(默认 Snappy)压缩
你不需要手动配置这些,Parquet 会自动选择最优编码方式。
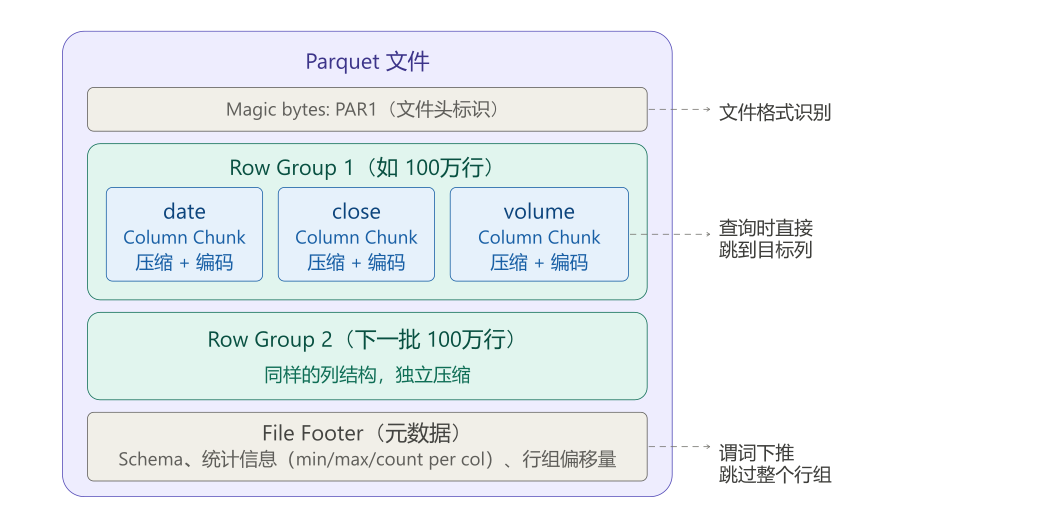
11.4.3 Schema:类型契约
Parquet 最被低估的特性是它携带了完整的数据类型信息(Schema)。这解决了 CSV 最常见的痛点:
import pyarrow as pa
import pyarrow.parquet as pq
# 读取 Parquet,查看它的 Schema
schema = pq.read_schema("fin_ratios.parquet")
print(schema)输出:
date: string
ticker: string ← 始终是字符串,"000001" 不会变成 1
roe: double
pe_ratio: double
revenue: double
industry: string对比 CSV 读入后需要手动修复的常见问题:
# CSV 读入后的典型问题
df_csv = pd.read_csv("fin_ratios.csv")
# 问题1:ticker 前导零丢失(如果原始数据没有加引号)
# "000001" → 1
# 问题2:date 列是字符串,不是 datetime
print(df_csv["date"].dtype) # object(字符串)
# 问题3:Wind 导出的 "--" 不会自动识别为 NaN
# df_csv["roe"].mean() 会报错
# 每次都要手动修复:
df_csv["date"] = pd.to_datetime(df_csv["date"])
df_csv["ticker"] = df_csv["ticker"].astype(str).str.zfill(6)
df_csv.replace("--", pd.NA, inplace=True)# Parquet 读入:类型直接正确,无需修复
df_pq = pd.read_parquet("fin_ratios.parquet")
print(df_pq.dtypes)
# date object
# ticker object ← 字符串,000001 完好
# roe float64 ← 直接可用11.4.4 读取时过滤:懒加载原则
核心原则:永远不要把整个文件读进内存再筛选,要先筛选再读入。
# 坏的做法:全量读入,再筛选(内存占用是有效数据的几十倍)
df_all = pd.read_parquet("fin_ratios.parquet")
df_bank = df_all[df_all["industry"] == "银行"] # 读了 100 万行,只用了 20 万行
# 好的做法:读取时就过滤
df_bank = pd.read_parquet(
"fin_ratios.parquet",
filters=[("industry", "==", "银行")] # 只加载银行行业的数据
)
# 同时只读需要的列
df_bank_roe = pd.read_parquet(
"fin_ratios.parquet",
columns=["date", "ticker", "roe"], # 只加载 3 列
filters=[("industry", "==", "银行")]
)11.4.5 分区存储:数据集发布的最佳实践
当数据量很大,或者需要在团队间共享时,按维度分区存储是标准做法:
df["year"] = pd.to_datetime(df["date"]).dt.year
# 按年份分区写入(生成独立的子文件夹)
df.to_parquet(
"data/processed/fin_ratios/",
partition_cols=["year"],
index=False
)生成的目录结构:
data/processed/fin_ratios/
├── year=2010/part-0.parquet (~9 MB)
├── year=2011/part-0.parquet (~9 MB)
├── ...
└── year=2023/part-0.parquet (~9 MB)这样做有两个优势:
- 用户只需要 2023 年的数据时,只下载
year=2023/文件夹,不需要下载完整数据集 - 放到 GitHub 仓库,单个文件都在 100 MB 以内,可以直接上传,无需 Git LFS
# 读取分区数据:只读指定年份,速度极快
df_2023 = pd.read_parquet(
"data/processed/fin_ratios/",
filters=[("year", "==", 2023)]
)11.4.6 把 CSV 发布为 Parquet:一个实用场景
如果你有一份 fin_ratios.csv(200 MB),想发布到 GitHub 供他人使用,可以先转为 Parquet,再附上转换说明:
# 你(数据提供方):一次性转换
df = pd.read_csv("fin_ratios.csv")
df.to_parquet("fin_ratios.parquet", compression="zstd", index=False)
# zstd 压缩率比默认的 snappy 更高,适合存档场景在 README 里附上这两行说明:
## 数据使用
数据以 Parquet 格式发布(约 40 MB),原始 CSV 约 200 MB。
**直接分析(推荐):**
```python
import pandas as pd
df = pd.read_parquet("fin_ratios.parquet")
```
**转换为 CSV(如需 Excel 查看):**
```python
import pandas as pd
pd.read_parquet("fin_ratios.parquet").to_csv("fin_ratios.csv", index=False)
```用户使用时,一行代码即可上手,不需要安装任何额外工具(pandas 已内置 Parquet 支持)。
我有一个 CSV 文件,路径是 [你的文件路径],包含以下列:
[列1(类型)、列2(类型)……]
其中有一些需要注意的问题:
- ticker 列是股票代码,需要保持字符串格式(保留前导零)
- date 列格式是 [YYYY-MM-DD / YYYYMMDD]
- 空值在原始文件中表示为 [– / N/A / 空字符串]
请帮我:
- 写一个读取和清洗这份 CSV 的函数,修复上述问题
- 将清洗后的数据按 [year / industry] 分区存为 Parquet
- 打印转换前后的文件大小对比
- 生成一段供他人使用的 README 说明(包含直接分析和转为 CSV 两种方式)
使用 pandas + pyarrow,代码需要有注释。
11.5 SQLite:嵌入式关系数据库
11.5.1 什么时候需要 SQLite
Parquet 解决了「大文件快速读取」的问题,但它不支持多表关联查询,也不支持数据的增删改。当你需要做类似这样的分析时,就需要 SQLite:
把日线行情数据和季度财务数据关联,筛选出 ROE > 15%、PE < 20 的股票,计算它们在财报发布后 30 天的平均超额收益。
这是一个典型的「行情表 × 财务表」联合查询,在 Parquet 中做需要把两个大文件都读进内存再手动合并,而在 SQLite 中一条 SQL 语句就能完成。
SQLite 的特点:
- 无需安装服务器:整个数据库就是一个
.db文件,可以直接发邮件或上传 - Python 标准库内置:
import sqlite3,不需要 pip install - 完整的 SQL 支持:JOIN、索引、聚合、窗口函数
- 适合规模:几十 GB 以内的数据都可以流畅运行
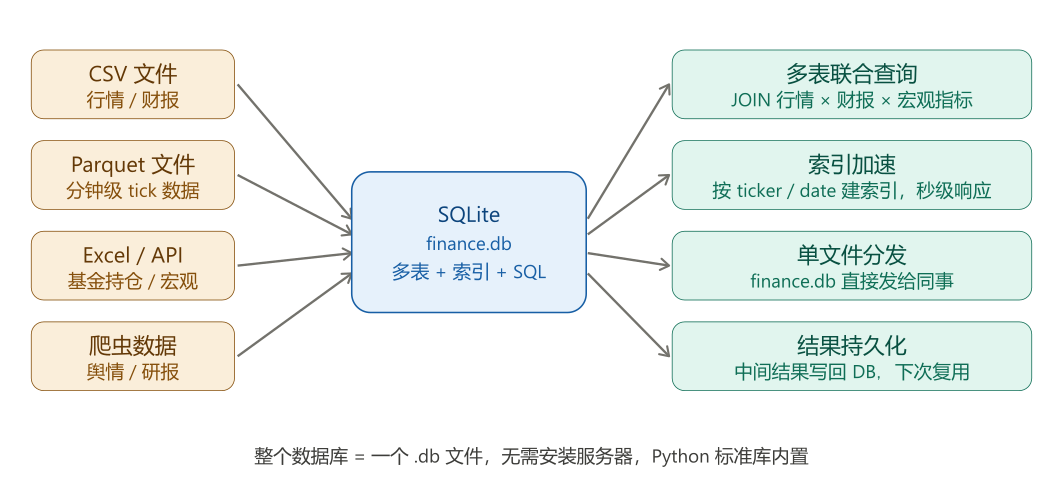
11.5.2 基本操作
import sqlite3
import pandas as pd
import numpy as np
# 创建数据库(文件不存在时自动创建)
conn = sqlite3.connect("finance.db")
cur = conn.cursor()
# 建表:股票日线
cur.execute("""
CREATE TABLE IF NOT EXISTS stock_daily (
date TEXT NOT NULL,
ticker TEXT NOT NULL,
close REAL,
volume INTEGER,
PRIMARY KEY (date, ticker)
)
""")
# 建表:季度财务数据
cur.execute("""
CREATE TABLE IF NOT EXISTS fin_quarterly (
ticker TEXT NOT NULL,
year INTEGER NOT NULL,
quarter INTEGER NOT NULL,
roe REAL,
pe_ratio REAL,
PRIMARY KEY (ticker, year, quarter)
)
""")
conn.commit()# 批量插入(pandas → SQLite,推荐用 to_sql)
np.random.seed(42)
df_daily = pd.DataFrame({
"date": pd.date_range("2023-01-01", periods=250).astype(str).tolist() * 10,
"ticker": [str(i).zfill(6) for i in range(10) for _ in range(250)],
"close": np.random.uniform(10, 100, 2500).round(2),
"volume": np.random.randint(1_000_000, 50_000_000, 2500),
})
df_daily.to_sql("stock_daily", conn, if_exists="append", index=False)
df_fin = pd.DataFrame({
"ticker": [str(i).zfill(6) for i in range(10) for _ in range(4)],
"year": [2023] * 40,
"quarter": [1, 2, 3, 4] * 10,
"roe": np.random.uniform(0.05, 0.25, 40).round(4),
"pe_ratio": np.random.uniform(8, 40, 40).round(2),
})
df_fin.to_sql("fin_quarterly", conn, if_exists="replace", index=False)
conn.commit()11.5.3 索引:查询加速的关键
建表之后,立刻建索引。索引对于「按 ticker 查询」这类操作,可以把速度从秒级提升到毫秒级:
# 在最常用的查询维度上建索引
cur.execute("""
CREATE INDEX IF NOT EXISTS idx_daily_ticker_date
ON stock_daily (ticker, date)
""")
conn.commit()
# 验证:查询单只股票的全年数据
import time
t0 = time.time()
df_result = pd.read_sql(
"SELECT * FROM stock_daily WHERE ticker = '000001'",
conn
)
print(f"查询耗时:{time.time() - t0:.4f} 秒,共 {len(df_result)} 行")11.5.4 多表联合查询
这是 SQLite 相对于 Parquet 最核心的优势:
# 关联行情与财务数据:找出 2023 年 ROE > 15%、PE < 20 的股票
# 并计算这些股票在 Q2 财报发布后的平均收盘价
df_combined = pd.read_sql("""
SELECT
d.ticker,
ROUND(AVG(d.close), 2) AS avg_close_h2,
f.roe,
f.pe_ratio
FROM stock_daily d
JOIN fin_quarterly f
ON d.ticker = f.ticker
AND f.year = 2023
AND f.quarter = 2
WHERE
f.roe > 0.15
AND f.pe_ratio < 20
AND d.date >= '2023-07-01'
AND d.date <= '2023-12-31'
GROUP BY
d.ticker, f.roe, f.pe_ratio
ORDER BY
f.roe DESC
""", conn)
print(df_combined)11.5.5 参数化查询
当查询条件来自用户输入或变量时,必须使用参数化查询,避免 SQL 注入风险:
# 错误做法(字符串拼接,有安全风险)
ticker = "000001"
df = pd.read_sql(f"SELECT * FROM stock_daily WHERE ticker = '{ticker}'", conn)
# 正确做法(参数化查询)
df = pd.read_sql(
"SELECT * FROM stock_daily WHERE ticker = ? AND date >= ?",
conn,
params=("000001", "2023-06-01")
)11.5.6 把分析结果写回数据库
SQLite 还可以用来存储中间结果,下次直接读取而不需要重新计算:
# 计算每只股票的月度均价(耗时操作)
df_monthly = pd.read_sql("""
SELECT
ticker,
SUBSTR(date, 1, 7) AS month,
ROUND(AVG(close), 2) AS avg_close,
ROUND(MAX(close), 2) AS max_close,
ROUND(MIN(close), 2) AS min_close,
SUM(volume) AS total_vol
FROM stock_daily
GROUP BY ticker, month
""", conn)
# 写回数据库,下次直接读,不需要重新聚合
df_monthly.to_sql("monthly_summary", conn, if_exists="replace", index=False)
conn.commit()
conn.close()我有一个 SQLite 数据库 finance.db,包含以下表:
stock_daily 表(股票日线数据): - date(TEXT,格式 YYYY-MM-DD) - ticker(TEXT,6 位股票代码) - close(REAL,收盘价) - volume(INTEGER,成交量)
fin_quarterly 表(季度财务数据): - ticker(TEXT) - year(INTEGER) - quarter(INTEGER,1-4) - roe(REAL,净资产收益率,小数形式) - pe_ratio(REAL,市盈率)
我想完成以下分析:[用自然语言描述你的分析目标,例如:找出 2023 年全年 ROE 持续大于 12% 的股票,计算它们在每个季报发布后一个月内的平均涨跌幅]
请帮我:
- 写出完成这个分析的 SQL 查询
- 用
pd.read_sql()封装成 Python 代码 - 解释每一个 JOIN 和 WHERE 条件的逻辑
- 说明应该在哪些列上建索引来加速查询
如果需要多步查询,请用 WITH 子句(CTE)组织。
11.6 DuckDB:对文件直接执行 SQL
11.6.1 一个常见的困境
你清洗好了数据,存成了 Parquet。现在想做一个跨文件的分析:把 5 年的日线数据(5 个 Parquet 文件)合并,计算每只股票的年化波动率。
传统做法是把 5 个文件都读进内存,合并成一个 DataFrame,再计算。但 5 年数据可能有几十 GB,内存放不下。
DuckDB 解决了这个问题:它可以直接对 Parquet 文件执行 SQL,不需要先把数据加载到内存,也不需要数据库服务器。
# pip install duckdb
import duckdb
# 直接对 Parquet 文件执行 SQL,不需要读入内存
result = duckdb.execute("""
SELECT
ticker,
COUNT(*) AS trading_days,
ROUND(AVG(close), 2) AS avg_close,
ROUND(STDDEV(close) / AVG(close) * 100, 2) AS cv_pct
FROM read_parquet('data/processed/stock_daily_*.parquet')
WHERE date >= '2023-01-01'
GROUP BY ticker
ORDER BY cv_pct DESC
LIMIT 20
""").df() # .df() 直接返回 pandas DataFrame
print(result)read_parquet() 支持通配符,可以一次性读取多个文件,DuckDB 会自动并行处理,速度接近 Apache Spark,但配置极为简单。
11.6.2 跨文件 JOIN
DuckDB 甚至可以对不同目录下的多个 Parquet 文件做 JOIN:
result = duckdb.execute("""
SELECT
a.ticker,
a.date,
a.close,
b.roe,
b.pe_ratio
FROM read_parquet('data/processed/stock_daily.parquet') a
JOIN read_parquet('data/processed/fin_quarterly.parquet') b
ON a.ticker = b.ticker
AND YEAR(a.date::DATE) = b.year
WHERE
b.roe > 0.15
AND b.quarter = 4
ORDER BY a.date, a.ticker
""").df()11.6.3 DuckDB、SQLite 与 Parquet 的定位
三者之间不是竞争关系,而是互补:
| 场景 | 推荐工具 |
|---|---|
| 存储大规模分析数据,用于共享 | Parquet |
| 跨多个 Parquet 文件做 SQL 分析 | DuckDB |
| 需要频繁增删改,多表长期维护 | SQLite |
| 生成结果给非技术人员查看 | CSV / Excel |
一个典型的工作流是:原始数据存 Parquet → 用 DuckDB 做探索性分析和因子计算 → 把需要长期维护的多表关系放进 SQLite → 最终结果导出 CSV 给导师或报告。
我有多个 Parquet 文件,存放在 [目录路径],文件命名规律是 [例如:stock_daily_YYYY.parquet]。
每个文件的列结构如下:
- [列1]:[类型和说明]
- [列2]:[类型和说明]
我想完成的分析是:[用自然语言描述,例如:计算每只股票过去 5 年的年化收益率和最大回撤,按收益率降序排列,取前 50 名]
请帮我:
- 用 DuckDB 的
read_parquet()读取所有文件(用通配符) - 写出完成分析的 SQL 查询
- 用
.df()转为 pandas DataFrame 方便后续处理 - 如果分析结果需要保存,说明应该存成 Parquet 还是 SQLite,理由是什么
如果涉及窗口函数(如计算移动平均、最大回撤),请用注释解释每个窗口函数的逻辑。
11.7 端到端工作流
把本章所有内容串联起来,形成一套可复用的完整流程。
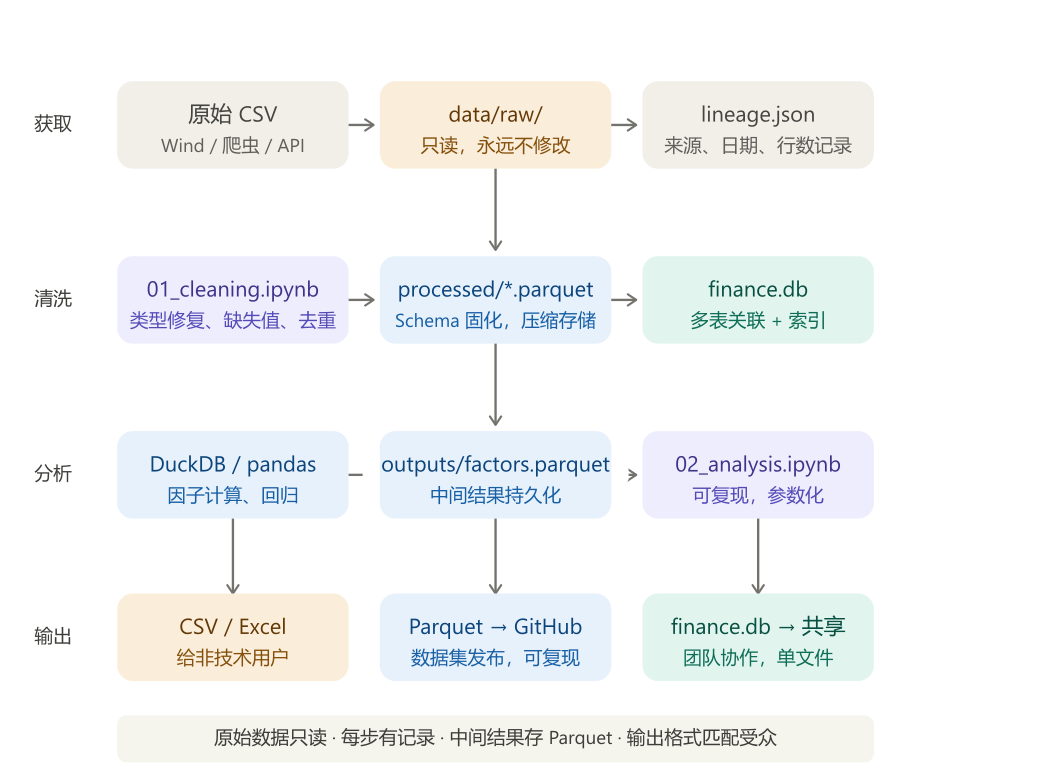
11.7.1 清洗函数:固化处理步骤
任何数据清洗都应该写成函数,而不是散落在 Notebook 的各个 Cell 里。函数化的好处是:任何人运行同一个函数,结果完全相同——这就是可复现性。
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
import json
import datetime
import os
def clean_and_save(
raw_path: str,
output_path: str,
source_desc: str = "",
na_values: list = None,
) -> pd.DataFrame:
"""
标准化清洗流程:读取原始 CSV → 修复类型 → 存为 Parquet → 记录元数据
参数:
raw_path : 原始 CSV 文件路径
output_path : 输出 Parquet 文件路径
source_desc : 数据来源描述(写入元数据)
na_values : 额外的空值标记(如 Wind 的 "--")
返回:
清洗后的 DataFrame
"""
# 1. 读取,识别空值
_na = ["--", "N/A", "n/a", "#N/A"] + (na_values or [])
df = pd.read_csv(raw_path, na_values=_na, dtype={"ticker": str})
# 2. 统一列名(小写 + 下划线)
df.columns = (
df.columns.str.strip()
.str.lower()
.str.replace(r"\s+", "_", regex=True)
)
# 3. 修复 ticker(补前导零至 6 位)
if "ticker" in df.columns:
df["ticker"] = df["ticker"].str.zfill(6)
# 4. 修复 date 列
if "date" in df.columns:
df["date"] = pd.to_datetime(df["date"], errors="coerce")
# 5. 存为 Parquet
os.makedirs(os.path.dirname(output_path) or ".", exist_ok=True)
df.to_parquet(output_path, index=False)
# 6. 记录元数据(lineage)
meta = {
"source_file": raw_path,
"output_file": output_path,
"source_desc": source_desc,
"created_at": datetime.datetime.now().isoformat(),
"row_count": len(df),
"columns": list(df.columns),
"date_range": (
f"{df['date'].min().date()} ~ {df['date'].max().date()}"
if "date" in df.columns else "N/A"
),
"null_counts": df.isnull().sum().to_dict(),
}
meta_path = output_path.replace(".parquet", "_lineage.json")
with open(meta_path, "w", encoding="utf-8") as f:
json.dump(meta, f, ensure_ascii=False, indent=2)
print(f"✓ 已保存:{output_path}")
print(f" 行数:{len(df):,},列数:{len(df.columns)}")
print(f" 元数据:{meta_path}")
return df使用示例:
df_daily = clean_and_save(
raw_path = "data/raw/wind_stock_daily_2023.csv",
output_path = "data/processed/stock_daily_2023.parquet",
source_desc = "Wind 金融终端,股票日线数据,2023年全年",
)11.7.2 从模拟数据到完整流程
以下用模拟数据演示「获取 → 清洗 → 分析 → 输出」的完整流程:
import duckdb
import sqlite3
# ── 第一步:生成模拟原始数据(模拟 Wind 导出) ──────────────────
np.random.seed(0)
n_stocks, n_days = 50, 500
tickers = [str(i).zfill(6) for i in range(1, n_stocks + 1)]
dates = pd.date_range("2022-01-01", periods=n_days, freq="B") # 工作日
rows = []
for t in tickers:
price = 50.0
for d in dates:
price *= np.random.uniform(0.97, 1.03)
rows.append({
"date": d.strftime("%Y-%m-%d"),
"ticker": t,
"close": round(price, 2),
"volume": int(np.random.randint(1_000_000, 10_000_000)),
})
pd.DataFrame(rows).to_csv("data/raw/stock_daily_raw.csv", index=False)
print("原始数据已生成")
# ── 第二步:清洗并存为 Parquet ──────────────────────────────────
df = clean_and_save(
raw_path = "data/raw/stock_daily_raw.csv",
output_path = "data/processed/stock_daily.parquet",
source_desc = "模拟数据,用于演示",
)
# ── 第三步:用 DuckDB 计算动量因子 ──────────────────────────────
df_momentum = duckdb.execute("""
WITH base AS (
SELECT
ticker,
date,
close,
-- 20 日前的收盘价(窗口函数)
LAG(close, 20) OVER (
PARTITION BY ticker
ORDER BY date
) AS close_20d_ago
FROM read_parquet('data/processed/stock_daily.parquet')
)
SELECT
ticker,
date,
close,
ROUND((close / close_20d_ago - 1) * 100, 2) AS momentum_20d
FROM base
WHERE close_20d_ago IS NOT NULL
ORDER BY date, ticker
""").df()
# ── 第四步:保存因子数据 ─────────────────────────────────────────
df_momentum.to_parquet("data/outputs/factor_momentum.parquet", index=False)
# ── 第五步:存入 SQLite,方便后续多表查询 ──────────────────────
conn = sqlite3.connect("finance.db")
df_momentum.to_sql("factor_momentum", conn, if_exists="replace", index=False)
conn.execute("""
CREATE INDEX IF NOT EXISTS idx_mom_ticker_date
ON factor_momentum (ticker, date)
""")
conn.commit()
conn.close()
print("\n完整流程执行完毕")
print(f" 因子数据:{len(df_momentum):,} 行")11.7.3 常见坑与检查清单
完成数据清洗后,用以下清单自查:
def data_quality_check(df: pd.DataFrame, name: str = "数据集"):
"""快速数据质量检查"""
print(f"\n{'='*40}")
print(f" {name} 质量报告")
print(f"{'='*40}")
print(f" 行数:{len(df):,} 列数:{len(df.columns)}")
print(f"\n 列类型:")
for col, dtype in df.dtypes.items():
null_n = df[col].isnull().sum()
null_pct = null_n / len(df) * 100
flag = " ⚠️" if null_pct > 5 else ""
print(f" {col:<20} {str(dtype):<12} 空值:{null_pct:.1f}%{flag}")
# 检查 ticker 前导零
if "ticker" in df.columns:
bad = df["ticker"].dropna()
bad = bad[bad.str.len() != 6]
if len(bad) > 0:
print(f"\n ⚠️ ticker 长度不为 6 的记录:{len(bad)} 条")
print(f" 示例:{bad.head(3).tolist()}")
# 检查 date 列
if "date" in df.columns and pd.api.types.is_datetime64_any_dtype(df["date"]):
print(f"\n 日期范围:{df['date'].min().date()} ~ {df['date'].max().date()}")
# 检查重复行
dup = df.duplicated().sum()
if dup > 0:
print(f"\n ⚠️ 重复行:{dup} 条")
print(f"{'='*40}\n")
# 使用
data_quality_check(df_momentum, "动量因子数据")我在处理一份金融数据时遇到了以下问题(可多选):
我的数据基本信息:
- 文件路径:[路径]
- 数据来源:[Wind / tushare / 自己爬取]
- 大概行数:[行数]
- 列名:[列名列表]
请帮我写一个函数,检测并修复上述问题,最后输出一份数据质量报告,说明修复了哪些问题、每列的空值比例、日期范围等关键信息。
11.8 本章小结
| 工具 / 概念 | 核心价值 | 记住这一句 |
|---|---|---|
| 文件命名规范 | 防止混乱,支持协作 | 日期用 YYYYMMDD,不用「最终版」 |
| Parquet | 压缩、快速、携带类型 | 分析用 Parquet,传阅用 CSV |
| SQLite | 多表关联,单文件数据库 | 不需要服务器,.db 文件即数据库 |
| DuckDB | 对 Parquet 直接跑 SQL | 不读进内存,直接查文件 |
| 懒加载原则 | 节省内存和时间 | 先筛选再读入,不要全量加载 |
| 数据血缘 | 可追溯,可复现 | 每份数据都能回答:从哪来、经过什么处理 |
本章介绍的各类数据管理工具对比如下:
| CSV | Parquet | SQLite | MySQL/PG | |
|---|---|---|---|---|
| 存储方式 | 行式文本 | 列式二进制 | 行式二进制 | 行式 + 索引 |
| 文件大小 | ⭐⭐(大) | ⭐⭐⭐⭐⭐(最小) | ⭐⭐⭐(中) | 需服务器 |
| 列查询速度 | 慢 | 极快(列跳过) | 快(有索引) | 快(有索引) |
| 多表 JOIN | ❌ | ❌(需 Spark) | ✅ 完整 SQL | ✅ 完整 SQL |
| CRUD 更新 | ❌ | ❌(追加写) | ✅ | ✅ |
| 并发写入 | — | — | 有限 | ✅ |
| 安装部署 | 无需 | pip install | Python 内置 | 需服务器 |
| 数据量上限 | ~GB | TB 级 | ~几十 GB | TB+ |
| 典型场景 | 小数据交换 Excel 兼容 |
大规模 分析查询 |
本地 DB 原型开发 |
生产系统 多用户并发 |
下一章将使用真实的 A 股数据,把本章介绍的所有工具应用到一个完整的研究项目中:从 Wind 原始数据出发,经过清洗、存储、因子计算,最终完成一个可发表的实证分析。