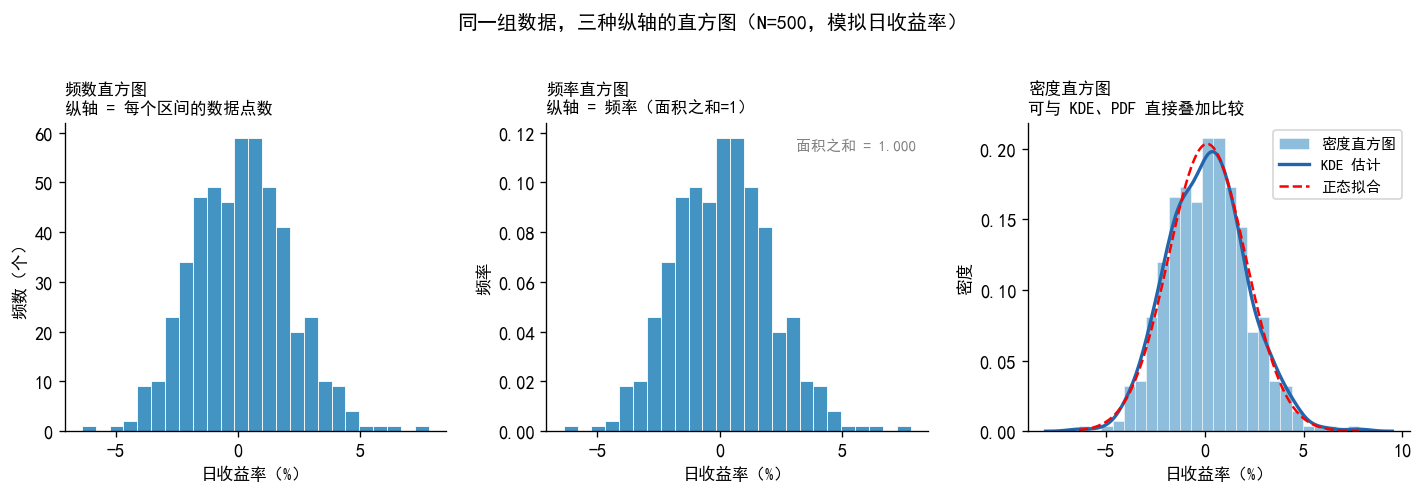
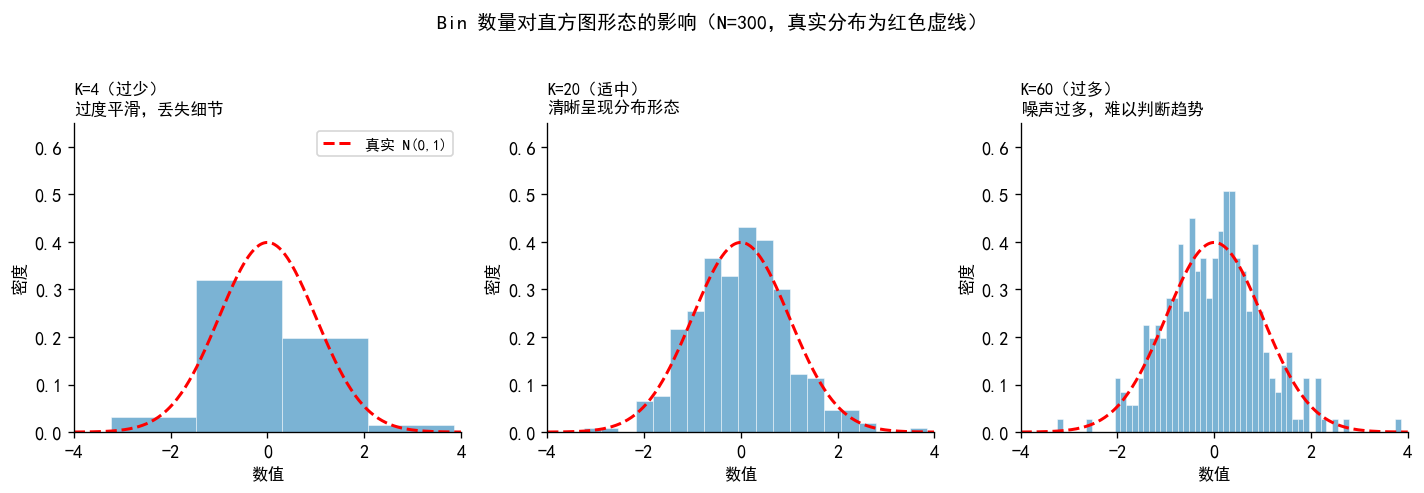
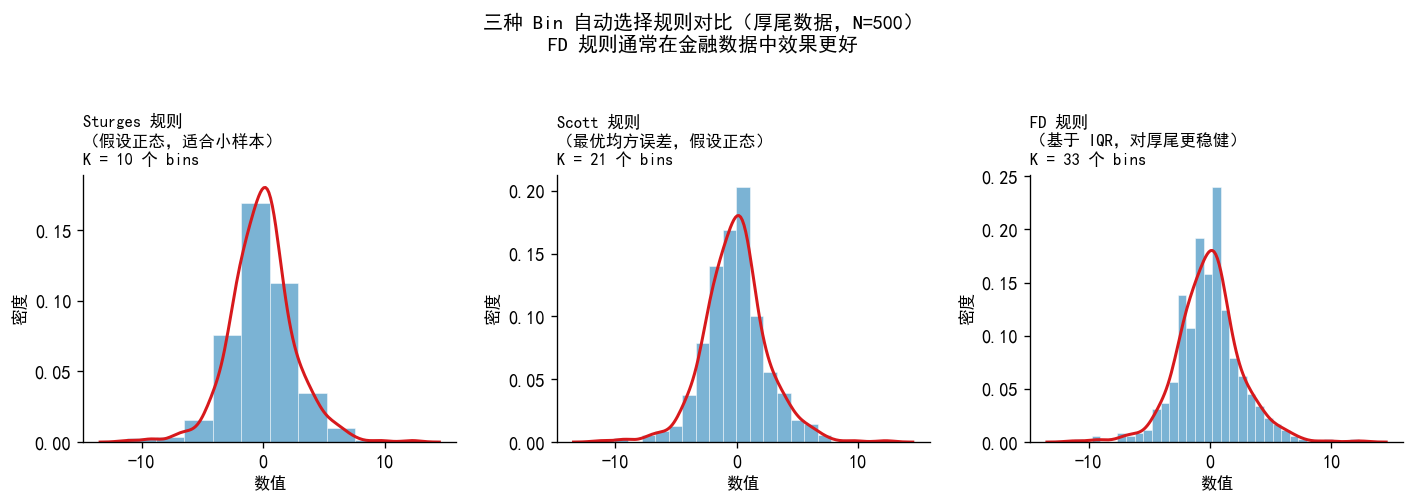
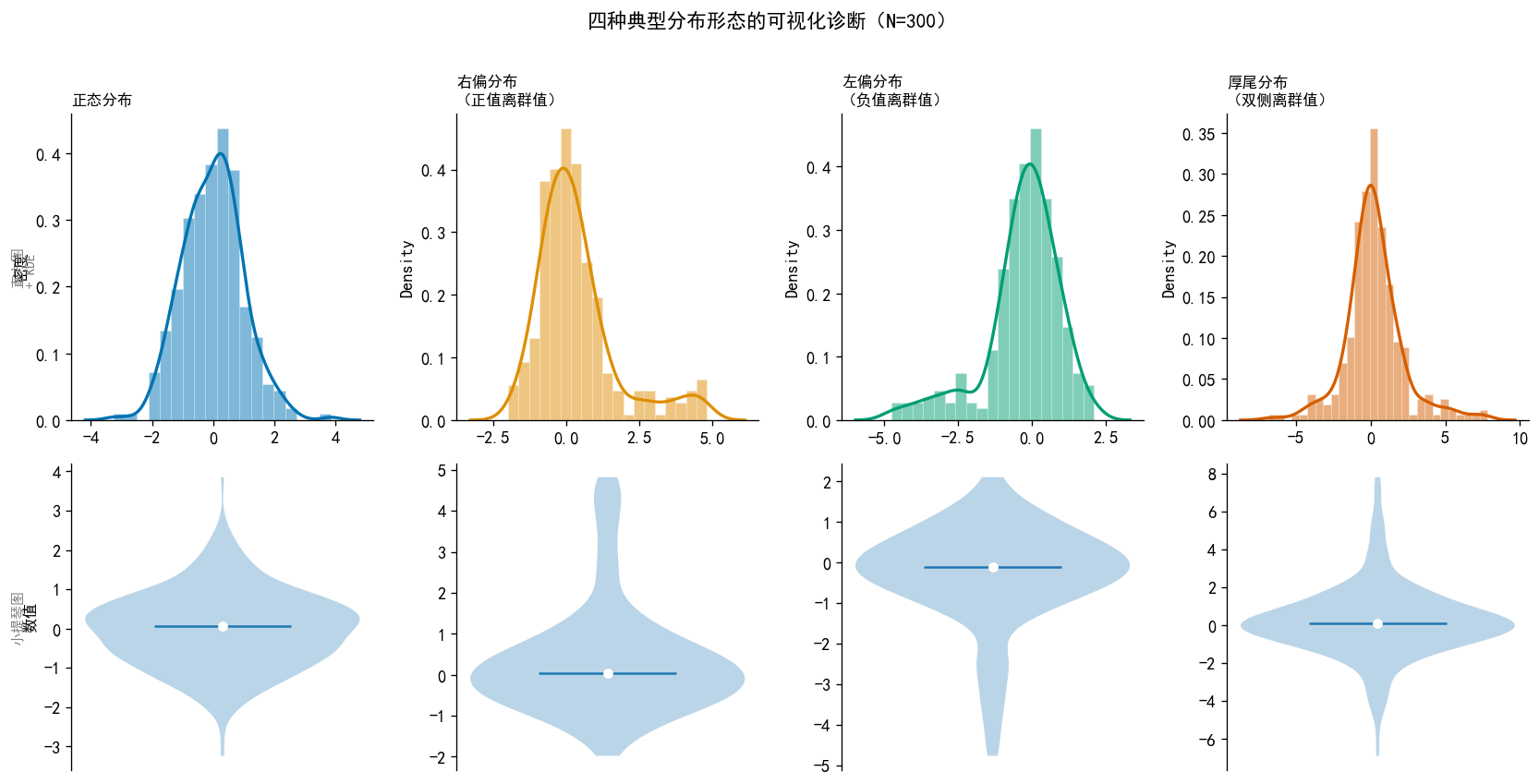
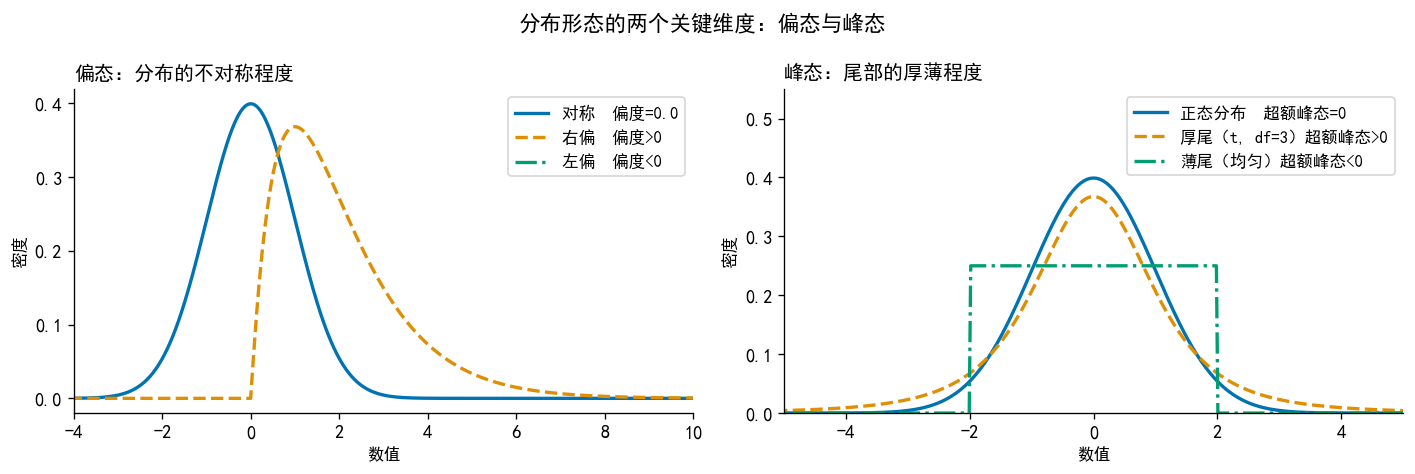
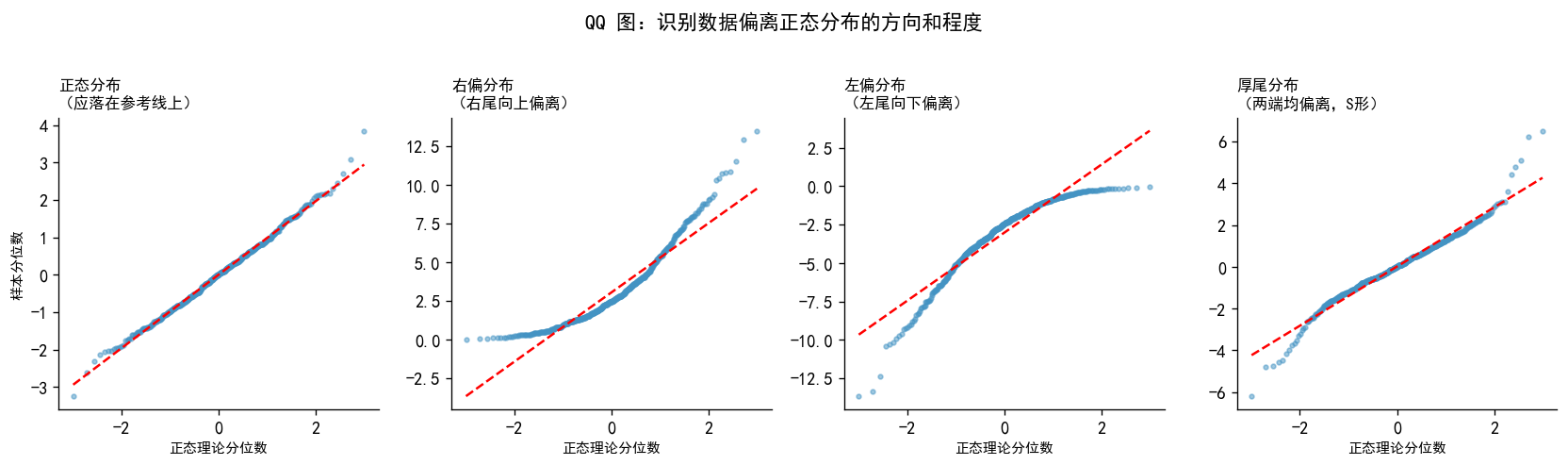
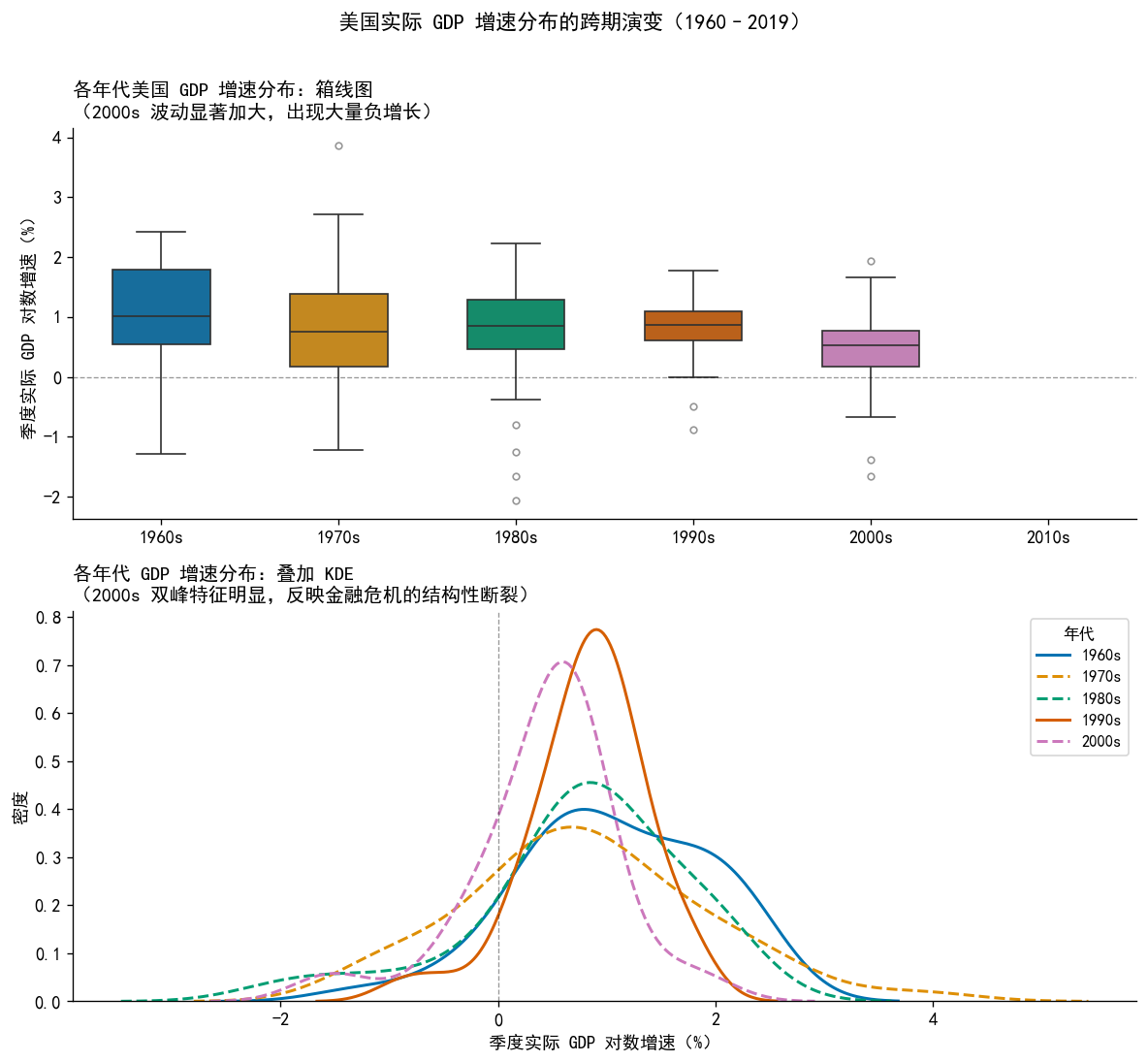
np.random.seed(42)
N = 300
# 四种分布
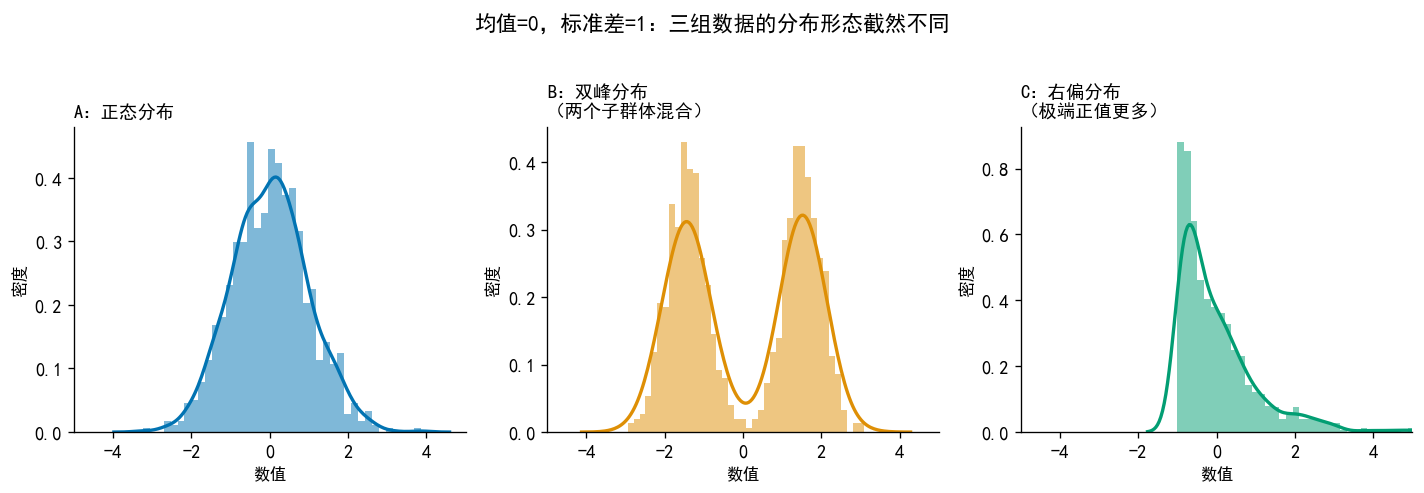
dist_names = ['正态分布', '右偏分布\n(正值离群值)', '左偏分布\n(负值离群值)', '厚尾分布\n(双侧离群值)']
x1 = np.random.normal(0, 1, N)
x2 = np.concatenate([np.random.normal(0, 0.8, int(N*0.9)),
np.random.uniform(2, 5, int(N*0.1))]) # 右偏
x3 = np.concatenate([np.random.normal(0, 0.8, int(N*0.9)),
np.random.uniform(-5, -2, int(N*0.1))]) # 左偏
x4 = stats.t.rvs(df=2, size=N) # 厚尾
datasets = [x1, x2, x3, x4]
# 打印描述统计
print(f'{"分布":12s} {"均值":>8s} {"标准差":>8s} {"偏度":>8s} {"超额峰态":>8s}')
for name, d in zip(dist_names, datasets):
label = name.split('\n')[0]
print(f'{label:12s} {d.mean():8.3f} {d.std():8.3f} '
f'{stats.skew(d):8.3f} {stats.kurtosis(d):8.3f}')
# ── 绘图:2行4列 ──────────────────────────────────────────
fig, axes = plt.subplots(2, 4, figsize=(14, 7))
colors = sns.color_palette('colorblind', 4)
for col, (name, data, color) in enumerate(zip(dist_names, datasets, colors)):
# 上行:直方图 + KDE
ax_top = axes[0, col]
ax_top.hist(data, bins='fd', density=True, color=color,
alpha=0.5, edgecolor='white', linewidth=0.3)
sns.kdeplot(data, ax=ax_top, color=color, linewidth=2)
ax_top.set_title(name, fontsize=10, fontweight='bold', loc='left')
ax_top.set_xlabel('')
if col == 0:
ax_top.set_ylabel('密度', fontsize=10)
sns.despine(ax=ax_top)
# 下行:小提琴图
ax_bot = axes[1, col]
ax_bot.violinplot(data, positions=[0], showmedians=True,
showextrema=False)
ax_bot.set_xticks([])
# 叠加箱线图核心统计量
q1, q2, q3 = np.percentile(data, [25, 50, 75])
ax_bot.scatter([0], [q2], color='white', s=30, zorder=3)
if col == 0:
ax_bot.set_ylabel('数值', fontsize=10)
sns.despine(ax=ax_bot, bottom=True)
axes[0, 0].text(-0.2, 0.5, '直方图\n+ KDE', transform=axes[0,0].transAxes,
rotation=90, va='center', fontsize=9, color='gray')
axes[1, 0].text(-0.2, 0.5, '小提琴图', transform=axes[1,0].transAxes,
rotation=90, va='center', fontsize=9, color='gray')
plt.suptitle('四种典型分布形态的可视化诊断(N=300)',
fontsize=13, fontweight='bold', y=1.01)
plt.tight_layout()
plt.show()