use "https://github.com/lianxhcn/data/raw/refs/heads/main/stata/Du2021EE_ERdata.dta", clear(Du et al. (2021, EE) https://doi.org/10.1016/j.eneco.2021.105247)本讲由浅入深地介绍三个模型,帮助大家理解变系数模型的基本思想及其与交互项模型、面板门槛模型的关系。
你会发现,引入交互项是最直接、最容易解释的变系数模型设定方法;而函数系数模型则有非常扎实的统计性质。相比之下,面板门槛模型基本上可以看作是变系数模型的一个特例 (即系数在某个门槛点发生不连续变化),实证分析中基本上可以放弃了。
考虑如下面板数据模型:
\[Y_{it} = \alpha_i + \gamma_{\color{red}{i}\color{blue}{t}} Z_{it} + X_{it}\beta + \mu_{it} \qquad \frac{\partial Y}{\partial Z} = \gamma_{it} \tag{1}\]
其中,\(i\)表示个体,\(t\)表示时间。基于理论分析,我们预期,\(Z\) 对 \(Y\) 的边际影响具有异质性,即 \({\partial Y}/{\partial Z}\) 会随着时间 \(t\) 和 (或) \(i\) 的变化而变化,表示为 \(\gamma_{it}\)。
显然,如果不做任何限制,\(\gamma_{it}\) 可以是任意形式的异质性,模型无法识别。一个基本思路是降维,我们可以假设 \(\gamma_{it}\) 仅与某个变量 \(U_{it}\) 有关,二者之间的函数关系为 \(\gamma(U_{it})\)。例如,我们可以假设 \(\gamma(U_{it})\) 是 \(U_{it}\) 的线性函数,即 \(\gamma(U_{it}) = \theta_0 + \theta_1 U_{it}\)。这里隐含的假设是,\(Z\) 对 \(Y\) 的边际影响随着 \(U\) 的变化而线性变化。其中,
\(\theta_0 = {\partial Y}/{\partial Z} \big|_{U=0}\),表示当 \(U=0\) 时,\(Z\) 对 \(Y\) 的边际影响;
\(\theta_1 = \frac{\partial({\partial Y}/{\partial Z})}{\partial {U}}\),表示 \(U\) 每增加一个单位,\(Z\) 对 \(Y\) 的边际影响的变化量,即 \(Z\) 对 \(Y\) 的边际影响如何随着 \(U\) 变化而变化。
同理,我们也可以假设 \(\gamma(U_{it})\) 是 \(U_{it}\) 的二次函数或三次函数等。至于选择什么样的函数形式,可以根据理论预期和数据特征来决定。
为不失一般性,这里以三次函数为例 (为了便于书写这里省去了下标),来说明这类变系数模型其实可以转化为一个包含交互项的线性回归模型。
\[ Y = {\color{red}{\gamma(U)}} Z + X\beta + \mu \tag{2a} \]
\[ {\color{red}{\gamma(U)}} = \theta_0 + \theta_1 U + \theta_2 U^2 + \theta_3 U^3 \tag{2b} \]
代入,可得:\(Y = Z(\theta_0 + \theta_1 U + \theta_2 U^2 + \theta_3 U^3) + X\beta + \mu\)
展开,可得:\(Y = \theta_0 Z + \theta_1 (Z\times U) + \theta_2 (Z\times U^2) + \theta_3 (Z\times U^3) + X\beta + \mu\)
如此以来,我们就将变系数模型转化为了一个包含交互项的普通线性回归模型。
xtreg 或 reghdfe 等命令来估计该线性回归模型,margins 命令来计算边际效应,以获得 \(\gamma(U)\) 的估计值,marginsplot 命令来绘制边际效应随 \(U\) 变化的图形。我们使用 Du et al. (2021) 文中的数据来演示如何估计上述变系数面板数据模型。
Du, K., Cheng, Y., & Yao, X. (2021). Environmental regulation, green technology innovation, and industrial structure upgrading: The road to the green transformation of Chinese cities. Energy Economics, 98, 105247. Link (rep), PDF, -Replication-, Google.
该文研究了环境规制 (\(Z\)) 对城市绿色转型 (\(Y\)) 的影响,调节变量为城市人均GDP (\(U\))。
\[ Y_{it}=\gamma\left(U_{i t-1}\right) Z_{i t-1}+\beta^{\prime} X_{i t-1}+\delta_i+\mu_{it} \tag{13} \]
use "https://github.com/lianxhcn/data/raw/refs/heads/main/stata/Du2021EE_ERdata.dta", clear(Du et al. (2021, EE) https://doi.org/10.1016/j.eneco.2021.105247)xtset
codebook cityno year gti er gdp lngti lngdp, compact
des gti er gdp
Panel variable: cityno (strongly balanced)
Time variable: year, 2002 to 2015
Delta: 1 unit
Variable Obs Unique Mean Min Max Label
-------------------------------------------------------------------------------
cityno 1470 105 53 1 105 City ID (105 environme...
year 1470 14 2008.5 2002 2015 Year
gti 1470 549 382.1381 0 13712 Green technology paten...
er 1470 1460 .0829945 .023842 .446886 ER: environmental regu...
gdp 1470 1456 29835.04 3347.96 127586 Real GDP per capita (2...
lngti 1470 548 4.322056 0 9.526027 lnGTI = ln(gti)
lngdp 1470 1456 10.08827 8.116106 11.75655 lnGDP = ln(gdp)
-------------------------------------------------------------------------------
Variable Storage Display Value
name type format label Variable label
-------------------------------------------------------------------------------
gti int %10.0g Green technology patents
(authorized, by application
date)
er double %10.0g ER: environmental regulation
index (entropy-weight
composite)
gdp double %10.0g Real GDP per capita (2001
constant prices)
global xlist "lnrd lnpop lnhc lninv lnfdi"
dropvars Z U
gen Z = er
gen U = lngdp
* xtreg lngti c.Z (c.U c.U#c.U c.U#c.U#c.U)#c.Z $xlist, fe robust
qui reghdfe lngti c.Z (c.U c.U#c.U c.U#c.U#c.U)#c.Z $xlist, ///
absorb(cityno) vce(cluster cityno)
esttab, nogapUnable to drop Z U
----------------------------
(1)
lngti
----------------------------
Z -1611.2
(-1.63)
c.U#c.Z 425.7
(1.49)
c.U#c.U#c.Z -37.82
(-1.37)
c.U#c.U#c.~Z 1.136
(1.27)
lnrd 0.783***
(6.10)
lnpop 2.203***
(5.44)
lnhc 0.452**
(2.98)
lninv 0.460**
(2.82)
lnfdi -0.0542
(-1.62)
_cons -12.87***
(-5.96)
----------------------------
N 1470
----------------------------
t statistics in parentheses
* p<0.05, ** p<0.01, *** p<0.001*-计算 γ(U) = ∂Y/∂Z 在不同 U 水平下的边际效应
margins, dydx(Z) at(U=(8(0.5)12)) // 0.5 -> 0.2
marginsplot, yline(0, lc(red) lp(dash))
/*-调整 U 的步长以获得更平滑的边际效应曲线
margins, dydx(Z) at(U=(8(0.1)12)) // 0.5 -> 0.2
marginsplot, yline(0, lc(red) lp(dash)) xlabel(8(0.5)12)
*/
Average marginal effects Number of obs = 1,470
Model VCE: Robust
Expression: Linear prediction, predict()
dy/dx wrt: Z
1._at: U = 8
2._at: U = 8.5
3._at: U = 9
4._at: U = 9.5
5._at: U = 10
6._at: U = 10.5
7._at: U = 11
8._at: U = 11.5
9._at: U = 12
------------------------------------------------------------------------------
| Delta-method
| dy/dx std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
Z |
_at |
1 | -44.191 13.469 -3.28 0.001 -70.590 -17.791
2 | -27.336 7.512 -3.64 0.000 -42.060 -12.613
3 | -14.910 3.917 -3.81 0.000 -22.587 -7.234
4 | -6.060 1.984 -3.05 0.002 -9.950 -2.171
5 | 0.065 1.205 0.05 0.957 -2.297 2.428
6 | 4.319 1.202 3.59 0.000 1.963 6.674
7 | 7.552 1.300 5.81 0.000 5.004 10.099
8 | 10.616 1.747 6.08 0.000 7.191 14.040
9 | 14.363 4.166 3.45 0.001 6.198 22.529
------------------------------------------------------------------------------
Variables that uniquely identify margins: U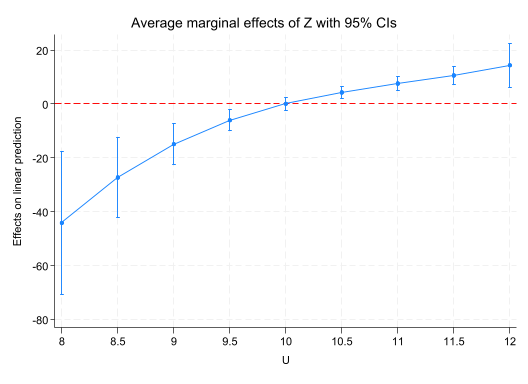
*-使用 xtplfc 命令:非参数估计
*----- 使用 xtplfc 估计
dropvars fcoe_*
xtplfc lngti $xlist, zvars(er) uvar(lngdp) ///
gen(fcoe_gti) power(3) nknots(2) quantile brep(200)
*----- 构造置信区间
gen fcoe_lb = fcoe_gti_1 - 1.96 * fcoe_gti_1_sd
gen fcoe_ub = fcoe_gti_1 + 1.96 * fcoe_gti_1_sd
*----- 绘图
twoway (rarea fcoe_lb fcoe_ub lngdp, color(blue%20) sort) ///
(line fcoe_gti_1 lngdp, lc(blue) lp(dash) sort), ///
yline(0, lc(red) lp(dash)) ///
xtitle("人均 GDP(对数)") ///
ytitle("边际效应 γ(lngdp)") ///
legend(order(1 "95% CI" 2 "γ(lngdp)") ///
ring(0) pos(5) c(1)) ///
scheme(s2mono)Unable to drop fcoe_*
Computing the bootstrap standard errors...
.................................................50
.................................................100
.................................................150
.................................................200
Partially linear functional-coefficient panel data model.
Fixed-effect series semiparametric estimation.
Estimation results: linear part Number of obs = 1365
Within R-squared = 0.1754
Adj Within R-squared = 0.1693
Root MSE = 0.4291
------------------------------------------------------------------------------
lngti | Coefficient Std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
lnrd | 0.089 0.053 1.68 0.092 -0.015 0.193
lnpop | 1.637 0.232 7.05 0.000 1.182 2.092
lnhc | 0.216 0.074 2.91 0.004 0.070 0.362
lninv | 0.392 0.077 5.11 0.000 0.242 0.543
lnfdi | 0.015 0.020 0.73 0.466 -0.025 0.054
------------------------------------------------------------------------------
Estimated functional coefficient(s) are saved in the data.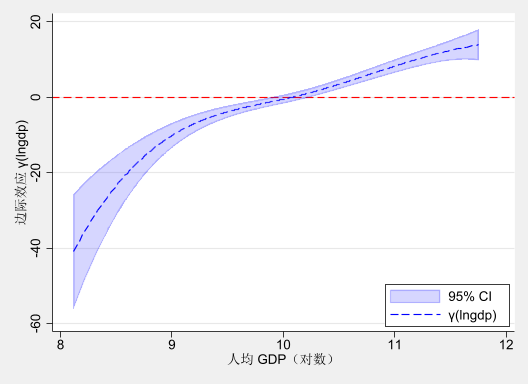
置信区间(灰色阴影):包含 0 表示边际效应不显著;不包含 0 表示边际效应显著。
典型模式:
*----- 生成显著性指示变量
cap drop significant
gen significant = 0
replace significant = 1 if fcoe_lb > 0 // 显著为正
replace significant = -1 if fcoe_ub < 0 // 显著为负
cap label drop sig_lab
label define sig_lab -1 "显著为负" 0 "不显著" 1 "显著为正"
label values significant sig_lab
qui sum lngdp if significant==-1
global left_bound: dis %3.2f `r(max)'
qui sum lngdp if significant==1
global right_bound: dis %3.2f `r(min)'
dis _skip(20) "不显著区间:[$left_bound, $right_bound]"
*----- 按显著性分段绘图
twoway (line fcoe_gti_1 lngdp if significant==1, lc(green) lw(*2) sort) ///
(line fcoe_gti_1 lngdp if significant==-1, lc(red) lw(*2) sort) ///
(line fcoe_gti_1 lngdp if significant==0, lc(black) lw(*2) lp(dash) sort) ///
(rarea fcoe_lb fcoe_ub lngdp, color(blue%15) sort), ///
yline(0, lcolor(black)) ///
xline($left_bound $right_bound, lc(gray) lp(dash)) ///
xtitle("人均 GDP(对数)") ///
ytitle("边际效应 γ(lngdp)") ///
title("边际效应的显著性分布") ///
xlabel(8 9 $left_bound 10 " " $right_bound 11 12) ///
legend(order(1 "显著为正" 2 "显著为负" 3 "不显著" 4 "95% CI") ///
ring(0) pos(5) c(1)) ///
scheme(s2mono)(631 real changes made)
(565 real changes made)
不显著区间:[9.89, 10.24]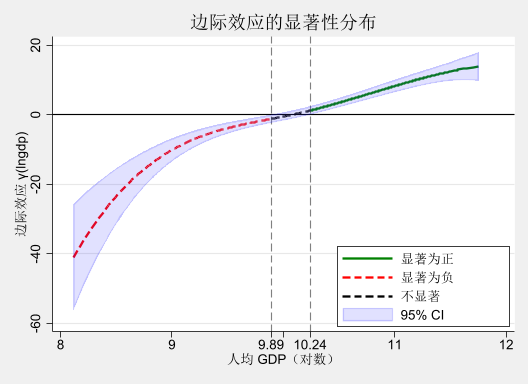
我们也可以使用 Hansen (1999) 提出的面板门槛模型来估计上述变系数面板数据模型。Stata 中可以使用 xthreg 命令来实现。
对应于 Du et al. (2021) 的问题背景,我们可以将单重面板门槛模型设定如下:
\[Y_{it} = \alpha_i + Z_{it}^{\prime} {\gamma}_1 \cdot I\left(U_{it} \leq \lambda\right) + Z_{it}^{\prime} {\gamma}_2 \cdot I\left(U_{it}>\lambda\right) + X_{it}\beta +\varepsilon_{it} \tag{1} \]
双重门槛模型包含两个门槛值:\(\lambda_1\) 和 \(\lambda_2\),设定如下:
\[ Y_{it} = \alpha_i + Z_{it}^{\prime} {\gamma}_1 \cdot I\left(U_{it} \leq \lambda_1\right) + Z_{it}^{\prime} {\gamma}_2 \cdot I\left(\lambda_1 < U_{it} \ge \lambda_2\right) + Z_{it}^{\prime} {\gamma}_3 \cdot I\left(U_{it} < \lambda_2\right) + X_{it}\beta +\varepsilon_{it} \tag{1} \]
use "https://github.com/lianxhcn/data/raw/refs/heads/main/stata/Du2021EE_ERdata.dta", clear(Du et al. (2021, EE) https://doi.org/10.1016/j.eneco.2021.105247)local xlist "lnrd lnpop lnhc lninv lnfdi"
xthreg lngti `xlist', rx(er) qx(lngdp) ///
thnum(2) ///
trim(0.10 0.10) ///
bs(500 500) nobslogEstimating the threshold parameters: 1st ...... 2nd ...... Done
Boostrapping for threshold effect test: 1st ...... 2nd ...... Done
Threshold estimator (level = 95):
-----------------------------------------------------
model | Threshold Lower Upper
-----------+-----------------------------------------
Th-1 | 10.3718 10.3260 10.3801
Th-21 | 10.3718 10.3260 10.3801
Th-22 | 9.3856 9.3739 9.3911
-----------------------------------------------------
Threshold effect test (bootstrap = 500 500):
-------------------------------------------------------------------------------
Threshold | RSS MSE Fstat Prob Crit10 Crit5 Crit1
-----------+-------------------------------------------------------------------
Single | 386.0885 0.2652 62.21 0.0000 32.6949 38.3816 46.3104
Double | 364.9414 0.2506 84.37 0.0000 21.5896 26.0920 38.6006
-------------------------------------------------------------------------------
Fixed-effects (within) regression Number of obs = 1,470
Group variable: cityno Number of groups = 105
R-squared: Obs per group:
Within = 0.8071 min = 14
Between = 0.7448 avg = 14.0
Overall = 0.7190 max = 14
F(8, 1357) = 709.49
corr(u_i, Xb) = -0.7395 Prob > F = 0.0000
------------------------------------------------------------------------------
lngti | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
lnrd | 0.900 0.052 17.17 0.000 0.797 1.003
lnpop | 2.220 0.188 11.82 0.000 1.852 2.589
lnhc | 0.650 0.061 10.71 0.000 0.531 0.769
lninv | 0.593 0.066 8.94 0.000 0.463 0.723
lnfdi | -0.082 0.022 -3.76 0.000 -0.124 -0.039
|
_cat#c.er |
0 | -5.941 1.076 -5.52 0.000 -8.053 -3.829
1 | 1.572 0.710 2.22 0.027 0.180 2.964
2 | 5.830 0.696 8.38 0.000 4.464 7.195
|
_cons | -14.485 1.136 -12.75 0.000 -16.713 -12.257
-------------+----------------------------------------------------------------
sigma_u | 1.2954211
sigma_e | .51868209
rho | .86183318 (fraction of variance due to u_i)
------------------------------------------------------------------------------
F test that all u_i=0: F(104, 1357) = 16.38 Prob > F = 0.0000eret list // 查看返回值,需要执行时去掉前面的 * 即可mat lambda = e(Thrss) //存储门槛值的矩阵
mat list lambda
lambda[3,5]
Threshold RSS Location Lower Upper
Th-1 10.381698 386.06067 198 10.326203 10.385701
Th-21 10.381698 363.50086 191 10.333359 10.385701
Th-22 9.3875656 363.50086 47 9.3775396 9.3958902*-记录门槛值 λ1 和 λ2
local lambda_1 = lambda[3,1] // Th-22
local lambda_2 = lambda[2,1] // Th-21
global lambda_1: dis %3.2f `lambda_1' // 保留两位小数存储
global lambda_2: dis %3.2f `lambda_2' // 保留两位小数存储
dis _skip(20) "门槛值:λ1 = ${lambda_1} , λ2 = ${lambda_2}" 门槛值:λ1 = 9.39 , λ2 = 10.38*-记录系数估计值 γ1, γ2, γ3
global gamma_1: dis %3.2f _b[0._cat#c.er]
global gamma_2: dis %3.2f _b[1._cat#c.er]
global gamma_3: dis %3.2f _b[2._cat#c.er]
dis _skip(20) "系数估计值:γ1 = ${gamma_1} , γ2 = ${gamma_2} , γ3 = ${gamma_3}" 系数估计值:γ1 = -6.13 , γ2 = 1.60 , γ3 = 5.90为了大家更好地理解变系数面板数据模型与面板门槛模型之间的联系,下面给出两者的对比图示。
我们先绘制面板门槛模型的估计结果,步骤如下:
*-三个区间的系数估计值
dropvars gamma* gamma*_lb gamma*_ub
gen gamma1 = _b[0._cat#c.er] if inrange(lngdp, ., $lambda_1)
gen gamma2 = _b[1._cat#c.er] if inrange(lngdp, $lambda_1, $lambda_2)
gen gamma3 = _b[2._cat#c.er] if inrange(lngdp, $lambda_2, .)
*-计算置信区间 = 估计值 ± 1.96*标准误
gen gamma1_lb = gamma1 - 1.96 * _se[0._cat#c.er]
gen gamma1_ub = gamma1 + 1.96 * _se[0._cat#c.er]
gen gamma2_lb = gamma2 - 1.96 * _se[1._cat#c.er]
gen gamma2_ub = gamma2 + 1.96 * _se[1._cat#c.er]
gen gamma3_lb = gamma3 - 1.96 * _se[2._cat#c.er]
gen gamma3_ub = gamma3 + 1.96 * _se[2._cat#c.er]
*----- 绘图
twoway (rarea gamma1_lb gamma1_ub lngdp, color(red%20) sort) ///
(rarea gamma2_lb gamma2_ub lngdp, color(green%20) sort) ///
(rarea gamma3_lb gamma3_ub lngdp, color(blue%20) sort) ///
(line gamma1 lngdp, lc(red) lp(solid) lw(*2) sort) ///
(line gamma2 lngdp, lc(green) lp(solid) lw(*2) sort) ///
(line gamma3 lngdp, lc(blue) lp(solid) lw(*2) sort) ///
, ///
yline(0, lc(black) lp(dash)) ///
xtitle("人均 GDP(对数)") ///
ytitle("边际效应 γ(lngdp)") ///
xline(${lambda_1} ${lambda_2}, lc(gray) lp(dash) lw(*0.4)) ///
xlabel(8 9 " " ${lambda_1} 10 " " ${lambda_2} 11 12) ///
legend(order(1 "γ1 95% CI" 2 "γ2 95% CI" 3 "γ3 95% CI") ///
ring(0) pos(5) c(1)) ///
scheme(s2mono)Unable to drop gamma*_lb gamma*_ub
(1,235 missing values generated)
(754 missing values generated)
(951 missing values generated)
(1,235 missing values generated)
(1,235 missing values generated)
(754 missing values generated)
(754 missing values generated)
(951 missing values generated)
(951 missing values generated)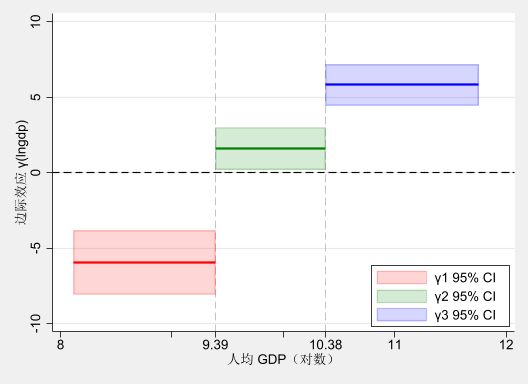
下图将变系数面板数据模型与面板门槛模型的估计结果进行了对比。从图中可以看出:
*----- 绘图
*local if1 "if inrange(fcoe_lb, -20, 20)"
*local if2 "if inrange(fcoe_gti_1, -20, 20)"
twoway (rarea gamma1_lb gamma1_ub lngdp, color(red%20) sort) ///
(rarea gamma2_lb gamma2_ub lngdp, color(green%20) sort) ///
(rarea gamma3_lb gamma3_ub lngdp, color(blue%20) sort) ///
(line gamma1 lngdp, lc(red) lp(solid) lw(*2) sort) ///
(line gamma2 lngdp, lc(green) lp(solid) lw(*2) sort) ///
(line gamma3 lngdp, lc(blue) lp(solid) lw(*2) sort) ///
(rarea fcoe_lb fcoe_ub lngdp `if1', color(gray%20) sort) ///
(line fcoe_gti_1 lngdp `if2', lc(yellow*2) lp(dash) lw(*2) sort) ///
, ///
yline(0, lc(red*0.5) lp(dash) lw(*0.6)) ///
xline($left_bound $right_bound, lc(gray) lp(dash) lw(*0.4)) ///
xline(${lambda_1} ${lambda_2}, lc(blue) lp(dash) lw(*0.4)) ///
xlabel(8 9 " " ${lambda_1} ${left_bound} 10 " " ///
${right_bound} ${lambda_2} 11 12, angle(50)) ///
xtitle("人均 GDP(对数)") ///
ytitle("边际效应 γ(lngdp)") ///
legend(order(1 "γ1 95% CI" 2 "γ2 95% CI" 3 "γ3 95% CI" 8 "xtplfc") ///
ring(0) pos(5) c(1)) ///
scheme(s2mono)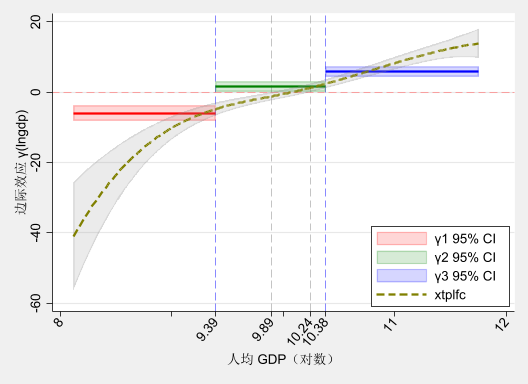
在实证分析中,建议优先采用变系数面板数据模型来刻画调节效应的异质性特征。当然,你也可以在稳健性检验中使用面板门槛模型来进行对比分析。
相比之下,门槛模型有如下几个劣势:
xthreg 中的选项 trim(0.1) 来实现)。该参数的选择存在很强的主观性,需要增加额外的稳健性测试。xthreg 中的选项 bsrep() 来实现),通常需要设定较大的抽样次数 (如 bsrep(1000)) 才能保证相对稳定的结果。