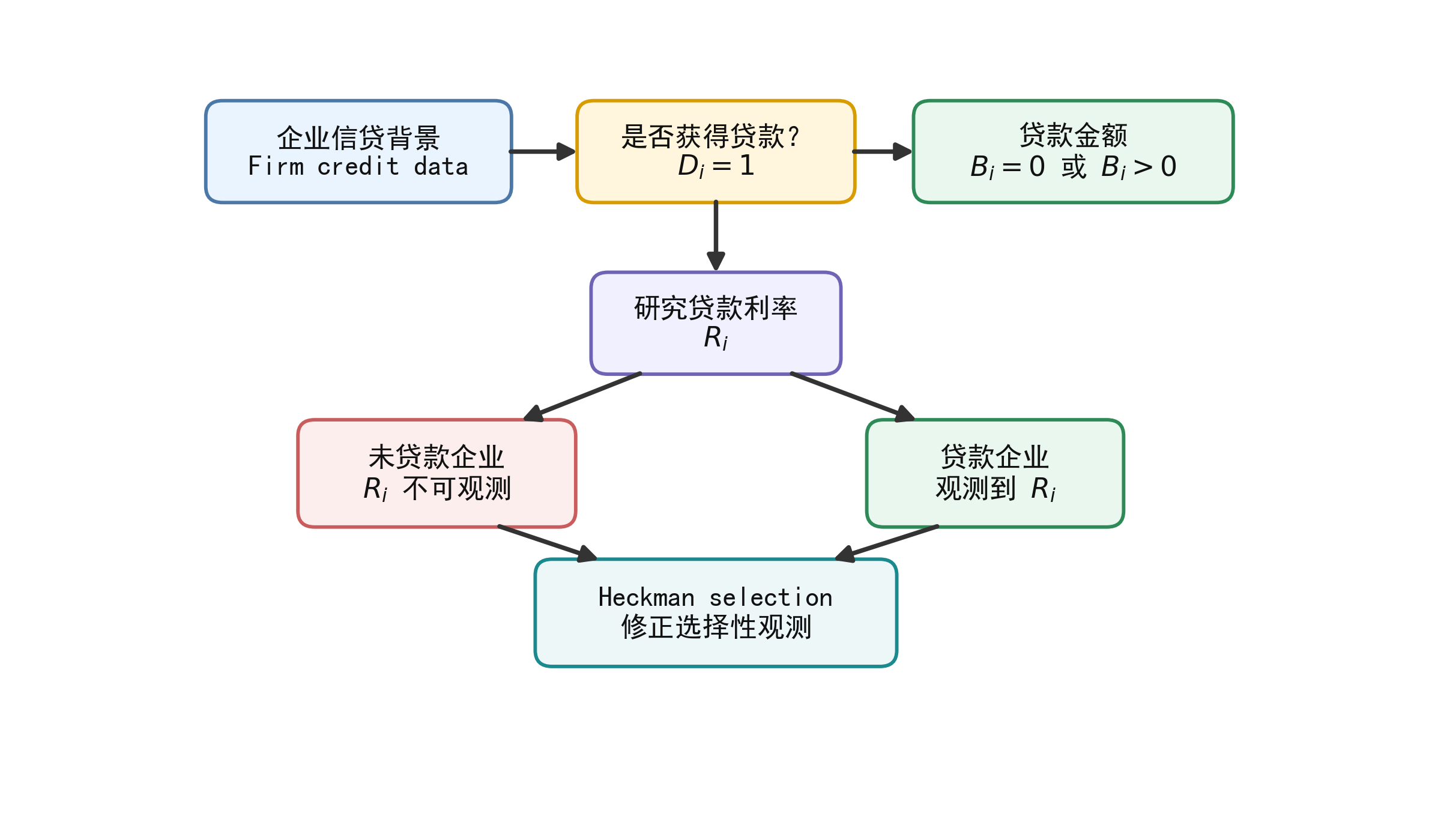
本章继续使用企业信贷背景。04 章把企业贷款金额中的大量 0 理解为潜在净借款需求在 0 处的归并;05 章把贷款金额中的 0 理解为真实的未贷款状态,并用 Two-part model 分开刻画“是否获得贷款”和“获得贷款后贷多少”。
本章的问题不同:我们不再研究贷款金额,而是研究 贷款利率 。对于没有获得贷款的企业,贷款金额可以记为 0;但贷款利率不是 0,而是根本不可观测。这个差别看似细小,却会改变整个模型设定。
本章的核心问题是:
如果结果变量只在被选择样本中可观测,而选择过程又不是随机的,直接在可观测样本上做 OLS 会发生什么?Heckman 模型如何修正这种选择性观测问题?
1. 问题起点:贷款金额为 0,贷款利率却是 missing
在企业信贷数据中,我们通常能看到两类企业:
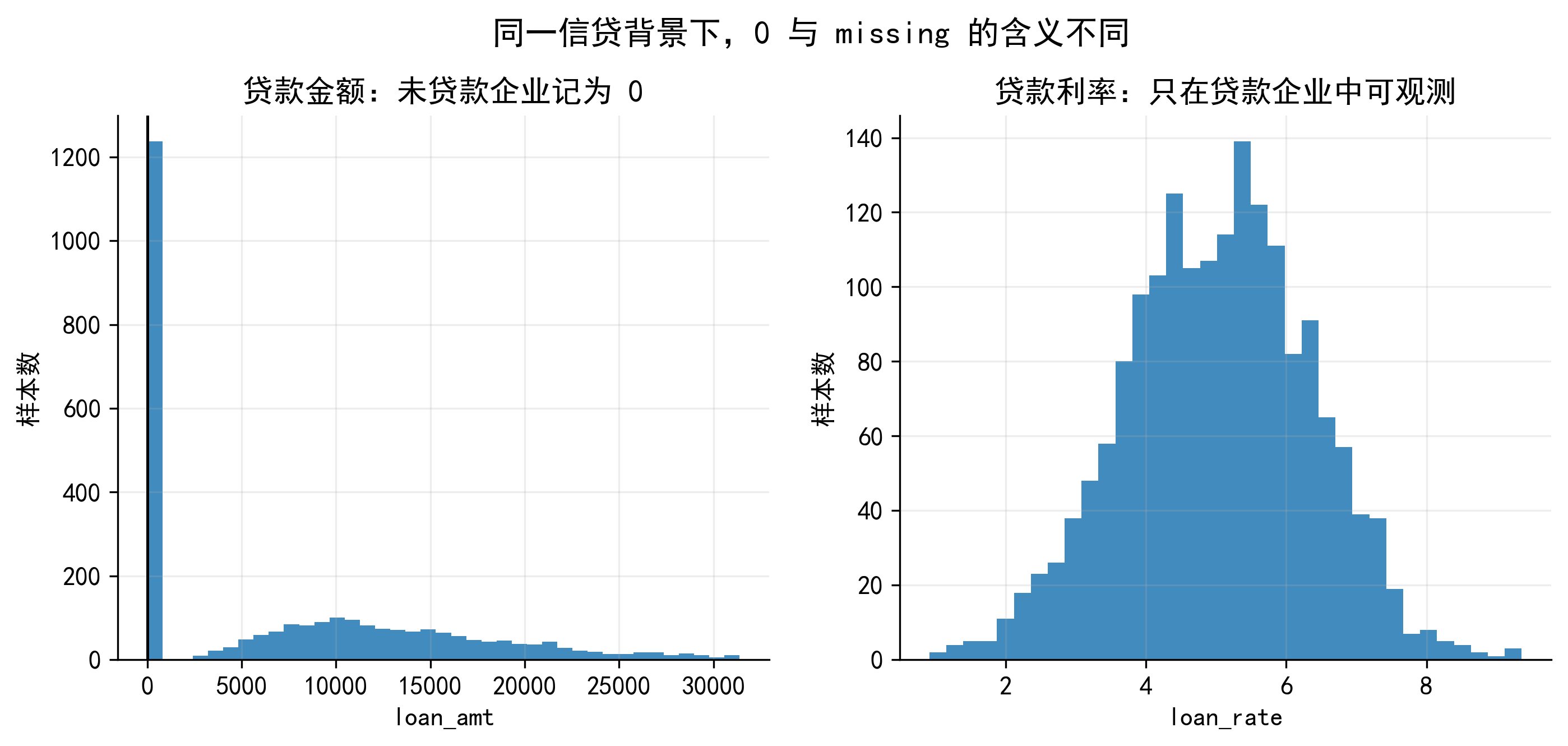
没有银行贷款的企业:贷款金额 \(B_i=0\) ;
有银行贷款的企业:贷款金额 \(B_i>0\) ,同时可以观察到贷款利率 \(R_i\) 。
如果研究对象是贷款金额,未贷款企业的结果可以自然记为 0。但如果研究对象是贷款利率,未贷款企业并不存在一笔贷款,因此也不存在相应的贷款利率。此时,\(R_i\) 不是 0,而是 missing。
如果我们定义一个新变量 D 表示贷款利率是否可观测,则典型的数据结构如下:
1
0.72
0.85
0.24
560
4.35
1
2
0.58
0.76
0.31
420
4.80
1
3
0.66
0.68
0.42
380
5.25
1
4
0.35
0.82
0.38
210
5.10
1
5
0.49
0.57
0.55
260
6.20
1
6
0.81
0.62
0.29
730
4.60
1
7
0.22
0.34
0.47
0
NA 0
8
0.18
0.28
0.63
0
NA 0
9
0.40
0.21
0.58
0
NA 0
10
0.27
0.44
0.72
0
NA 0
这就是样本选择问题的起点。
图中最重要的信息是:没有贷款的企业仍然在数据中,但它们的贷款利率不可观测。若只保留有贷款企业来估计贷款利率方程,样本就不再是总体企业的随机子样本。
Two-part model 和 Heckman selection 经常被混在一起,但它们处理的问题不同。
Two-part model:未参与者的结果为 0。例如未贷款企业的贷款金额是 0。
Heckman selection:未被选择者的结果变量不可观测 (缺失值)。例如未贷款企业的贷款利率不是 0,而是无法观测到这项结果。
因此,是否使用 Heckman,不取决于数据中有没有很多 0,而取决于研究对象是否只在被选择样本中可见。
需要特别说明的是,在使用 Heckman 模型时,收集数据时,我们仍然需要把未贷款企业保留下来,并且记录它们的特征变量(如抵押率、银行可达性、风险等级等)。如果在数据收集阶段就把未贷款企业剔除掉了,那么 Heckman 模型也无从谈起了。
在第一阶段的样本选择方程中,我们需要使用 D 作为被解释变量,来估计哪些特征会影响企业进入贷款关系,以及某家企业被选入的概率;在第二阶段的结果方程中,我们需要使用第一阶段的估计结果来修正选择性观测问题,来估计贷款利率方程中的参数。
2. 企业信贷案例:变量如何具体设定?
为了避免泛泛而谈,本章只使用三个核心变量。设:
\(D_i\) :企业是否获得银行贷款,\(D_i=1\) 表示获得贷款;\(R_i\) :企业贷款利率,只在 \(D_i=1\) 时可观测;\(collateral_i\) :抵押能力,例如可抵押资产比例;\(bank\_access_i\) :贷款可得性,例如本地银行网点密度、银企关系便利度或信贷服务覆盖程度;\(risk_i\) :企业风险,例如违约风险、盈利波动或信用风险评分。
本章的两个方程是:
\[
D_i^*
=
\gamma_0
+\gamma_1 collateral_i
+\gamma_2 bank\_access_i
-\gamma_3 risk_i
+v_i
\]
\[
D_i=1(D_i^*>0)
\]
以及:
\[
R_i
=
\beta_0
-\beta_1 collateral_i
+\beta_2 risk_i
+u_i,
\quad D_i=1
\]
这套设定的经济含义如下。
\(collateral_i\) 是
是
抵押能力越强,越容易获得贷款;在获得贷款后,抵押能力也可能降低贷款利率
\(bank\_access_i\) 是
否
银行可得性主要影响企业能否进入信贷关系,是排他性变量候选
\(risk_i\) 是
是
风险越高,越不容易获得贷款;获得贷款后,风险也会推高贷款利率
注意,这里没有堆很多控制变量。主例只保留能讲清楚机制的变量。实际论文中当然可以加入企业规模、年龄、行业固定效应、地区固定效应等,但教学主例不应让变量清单淹没模型逻辑。
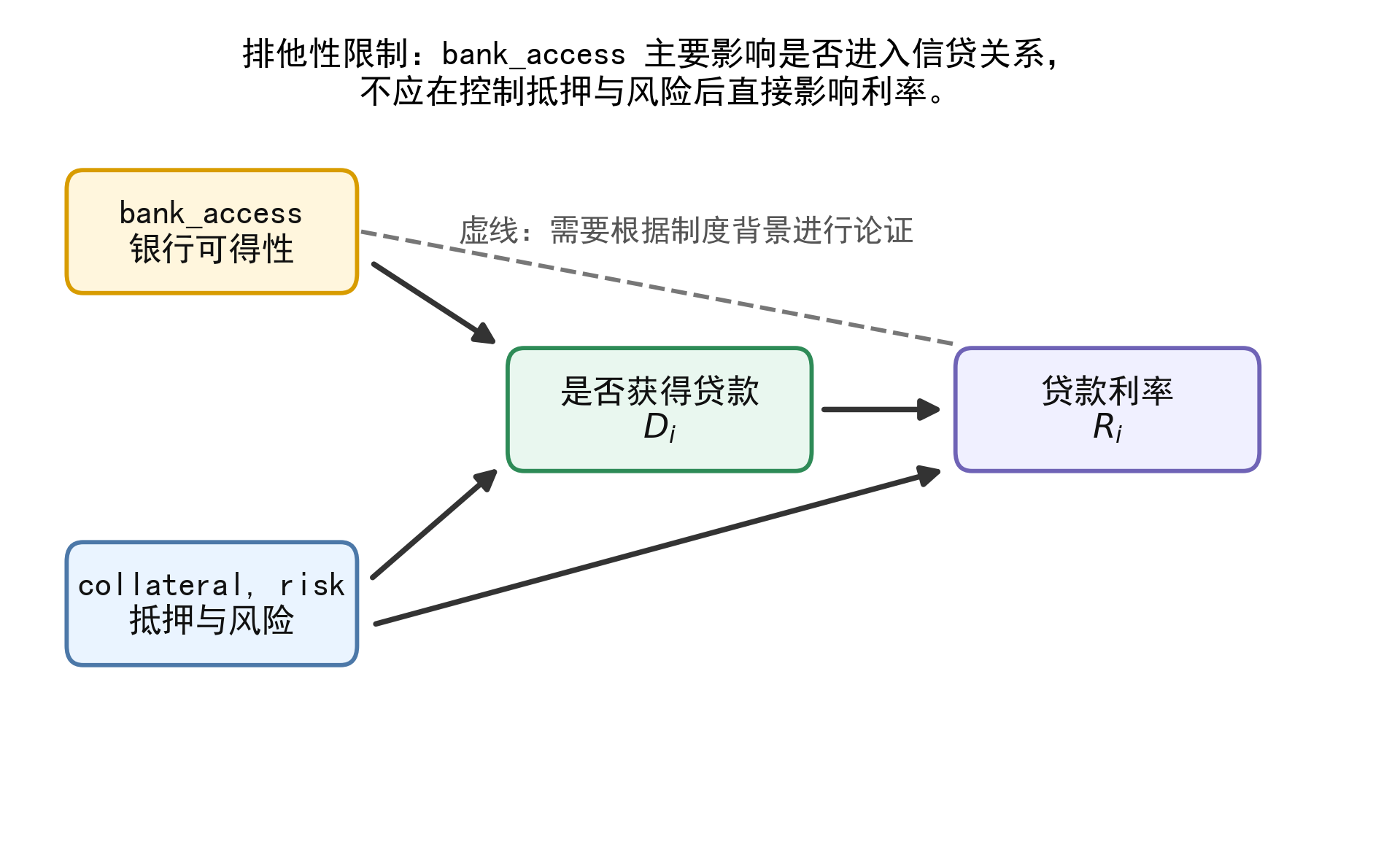
Heckman 模型最好有一个进入选择方程、但不直接进入结果方程的变量。这里的 \(bank\_access_i\) 是一个候选变量,因为它可以影响企业是否获得贷款:银行网点更多、信贷服务更便利、企业更容易接触银行客户经理,就更可能进入贷款流程。
但在控制抵押能力和风险以后,\(bank\_access_i\) 是否还直接影响贷款利率,需要用制度背景解释。如果银行网点密度同时改变银行竞争程度,并直接压低利率,那么它就不再是理想的排他性变量。
因此,排他性限制不是一个“统计显著性”问题,而是一个研究设计和制度解释问题。
3. 为什么只用贷款企业做 OLS 可能有偏?
若直接在贷款企业样本中估计:
\[
R_i
=
\beta_0
-\beta_1 collateral_i
+\beta_2 risk_i
+u_i,
\quad D_i=1
\]
OLS 需要的关键条件是:
\[
E(u_i\mid collateral_i,risk_i,D_i=1)=0
\]
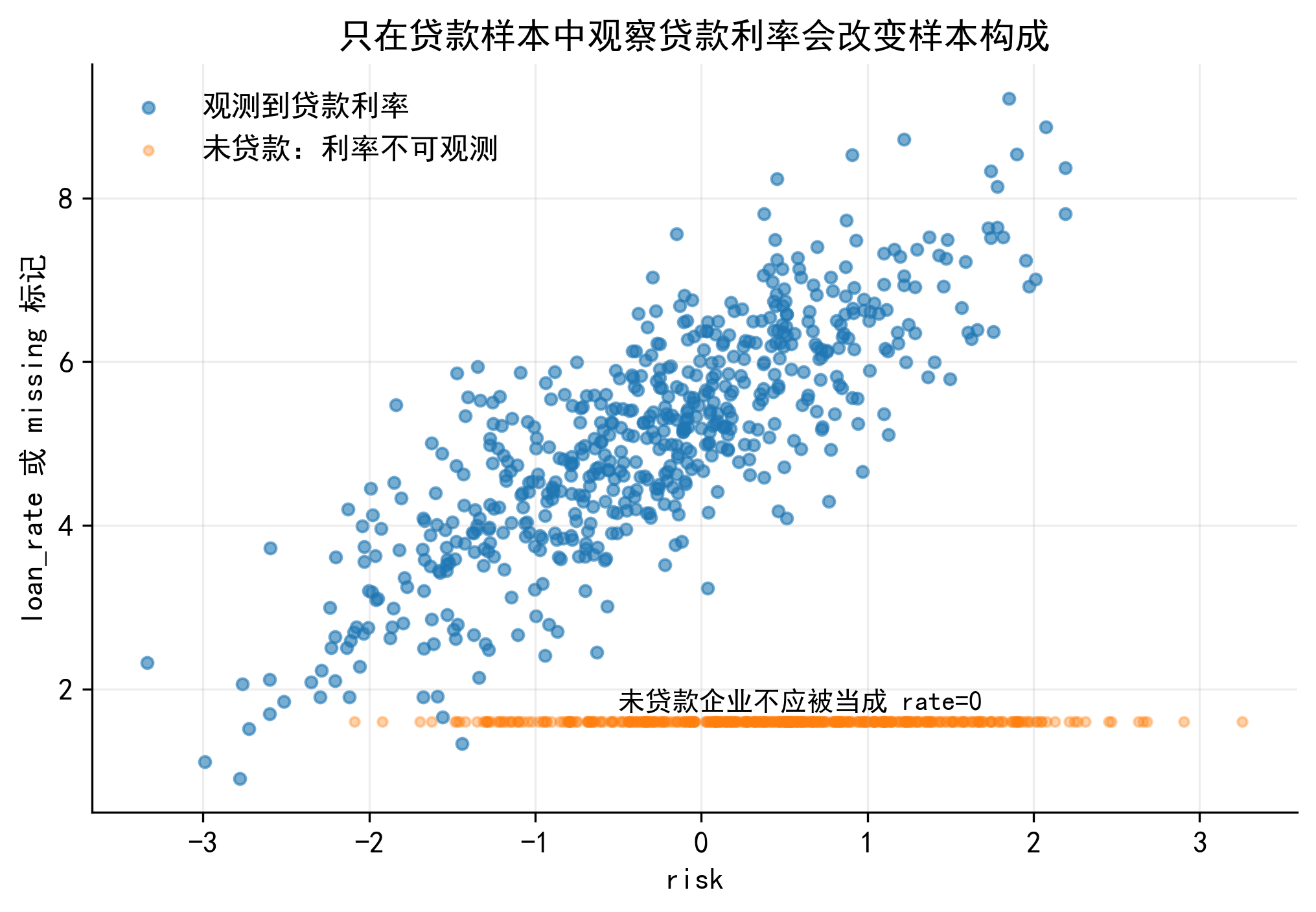
但如果企业获得贷款的未观测因素 \(v_i\) 与贷款利率方程的未观测因素 \(u_i\) 相关,这个条件通常不成立。
例如,某些企业有更好的银企关系或更高的信息透明度。这些特征可能同时:
提高企业获得贷款的概率;
降低企业获得贷款后的利率。
如果这些特征没有被研究者完全观测到,它们就会进入 \(v_i\) 和 \(u_i\) 。此时,\(u_i\) 与选择过程相关,只看贷款企业会导致误差项的条件均值不再为 0。
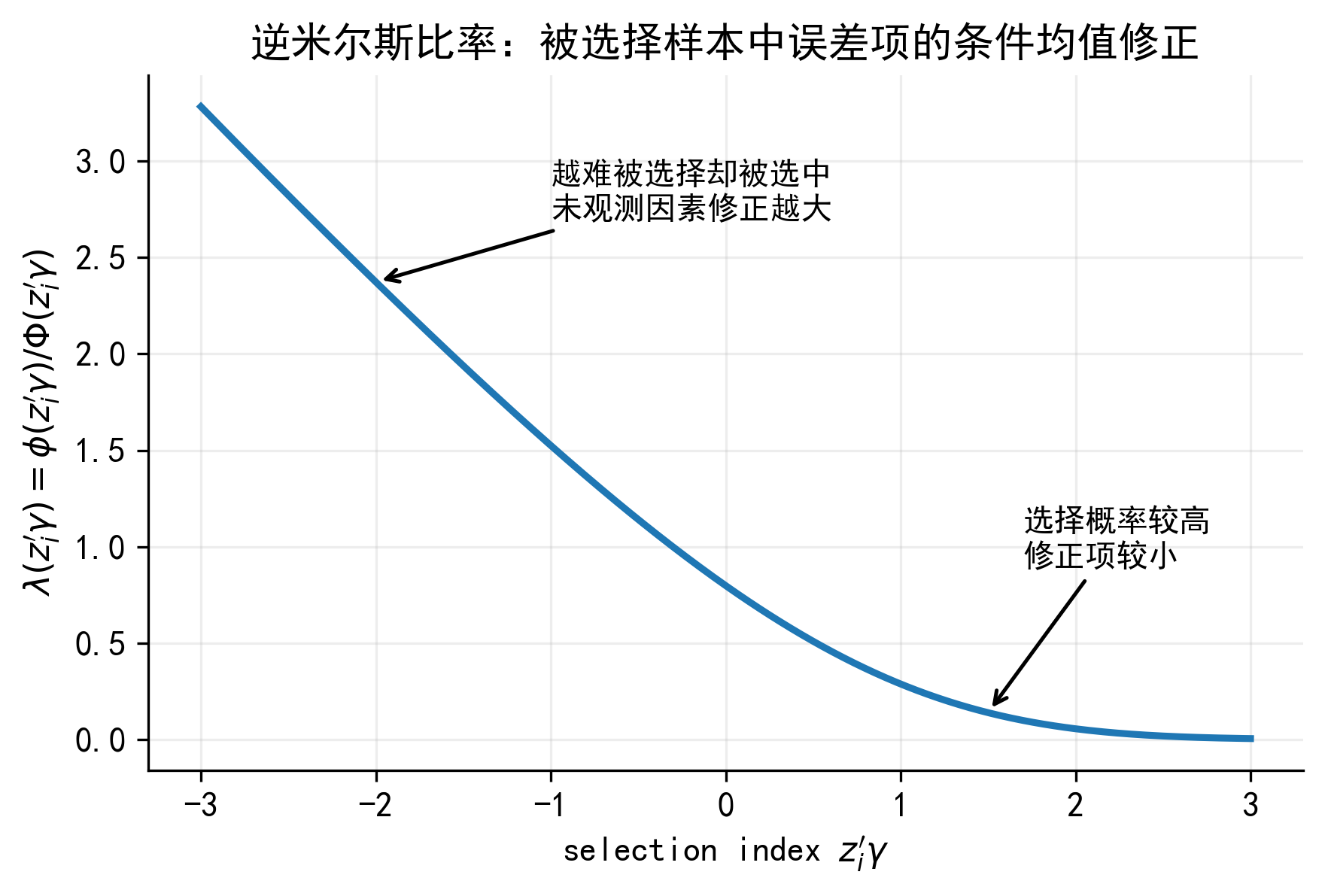
4. 逆米尔斯比率:选择性观测中的修正项
Heckman 模型和 Tobit 模型一样,会自然出现逆米尔斯比率。这里它的作用是修正“只在贷款企业中观察贷款利率”导致的误差项条件均值偏离。
设选择方程为:
\[
D_i^*=z_i'\gamma+v_i
\]
\[
D_i=1(D_i^*>0)
\]
结果方程为:
\[
R_i=x_i'\beta+u_i
\]
假设:
\[
\begin{pmatrix}
u_i\\
v_i
\end{pmatrix}
\sim
N
\left[
\begin{pmatrix}
0\\
0
\end{pmatrix},
\begin{pmatrix}
\sigma_u^2 & \rho\sigma_u\\
\rho\sigma_u & 1
\end{pmatrix}
\right]
\]
其中 \(v_i\) 的方差标准化为 1,这是 Probit 选择方程的常规设定。
在 \(D_i=1\) 的样本中,有:
\[
E(u_i\mid D_i=1,z_i)
=
\rho\sigma_u
\lambda(z_i'\gamma)
\]
其中:
\[
\lambda(z_i'\gamma)
=
\frac{\phi(z_i'\gamma)}
{\Phi(z_i'\gamma)}
\]
这就是逆米尔斯比率。
IMR 可以理解为:在已经进入被选择样本的人群中,未观测因素的平均修正项。
如果某个企业根据可观测条件 \(z_i'\gamma\) 来看并不容易获得贷款,但它最终仍然获得了贷款,那么它很可能具有一些研究者没有观测到的有利因素。这些未观测因素会进入选择方程的误差项 \(v_i\) 。
如果 \(v_i\) 与利率方程误差项 \(u_i\) 相关,那么这些未观测有利因素也会系统性影响贷款利率。IMR 正是在第二阶段把这种条件均值偏离补进去。
5. Heckman two-step:两步估计的逻辑
Heckman two-step 可以写成两个步骤。
5.1 第一步:估计选择方程
首先用所有企业估计 Probit:
\[
P(D_i=1\mid z_i)
=
\Phi(z_i'\gamma)
\]
得到 \(\hat\gamma\) 后,对每个贷款企业计算:
\[
\hat\lambda_i
=
\frac{\phi(z_i'\hat\gamma)}
{\Phi(z_i'\hat\gamma)}
\]
5.2 第二步:在贷款企业样本中加入 IMR
然后在 \(D_i=1\) 的样本中估计:
\[
R_i
=
x_i'\beta
+
\delta\hat\lambda_i
+
\varepsilon_i
\]
其中:
\[
\delta=\rho\sigma_u
\]
因此,\(\hat\lambda_i\) 的系数可以用来判断选择性观测是否重要。
如果 \(\delta=0\) ,说明选择方程误差与利率方程误差不相关,选择修正不重要;
如果 \(\delta\ne 0\) ,说明只用贷款企业估计利率方程时,可能存在选择性偏误。
需要注意:two-step 第二阶段中 \(\hat\lambda_i\) 是估计出来的生成变量,因此常规 OLS 标准误并不准确。实际应用中应使用专门的 Heckman 标准误、bootstrap 或软件命令提供的修正标准误。
6. MLE:把选择方程和结果方程联合起来
Heckman 模型也可以用最大似然估计。其基本思路是把 \(D_i=0\) 和 \(D_i=1\) 两类样本的似然贡献同时写出来。
对于没有贷款的企业,只有选择结果 \(D_i=0\) 被观察到,其似然贡献为:
\[
P(D_i=0\mid z_i)
=
\Phi(-z_i'\gamma)
\]
对于获得贷款的企业,我们同时观察到 \(D_i=1\) 和 \(R_i\) 。令:
\[
e_i=\frac{R_i-x_i'\beta}{\sigma_u}
\]
则其似然贡献可以写为:
\[
\frac{1}{\sigma_u}
\phi(e_i)
\Phi
\left(
\frac{
z_i'\gamma+\rho e_i
}
{
\sqrt{1-\rho^2}
}
\right)
\]
因此,完整对数似然为:
\[
\begin{aligned}
\ell(\beta,\gamma,\sigma_u,\rho)
=&
\sum_{D_i=0}
\log \Phi(-z_i'\gamma)\\
&+
\sum_{D_i=1}
\left[
-\log\sigma_u
+\log\phi(e_i)
+
\log\Phi
\left(
\frac{
z_i'\gamma+\rho e_i
}
{
\sqrt{1-\rho^2}
}
\right)
\right]
\end{aligned}
\]
MLE 的优点是效率更高,也能直接估计 \(\rho\) 。缺点是对联合正态假设更敏感,数值优化也比 two-step 更复杂。教学中通常先讲 two-step,因为它更能揭示选择修正的来源。
7. 结果如何解释?
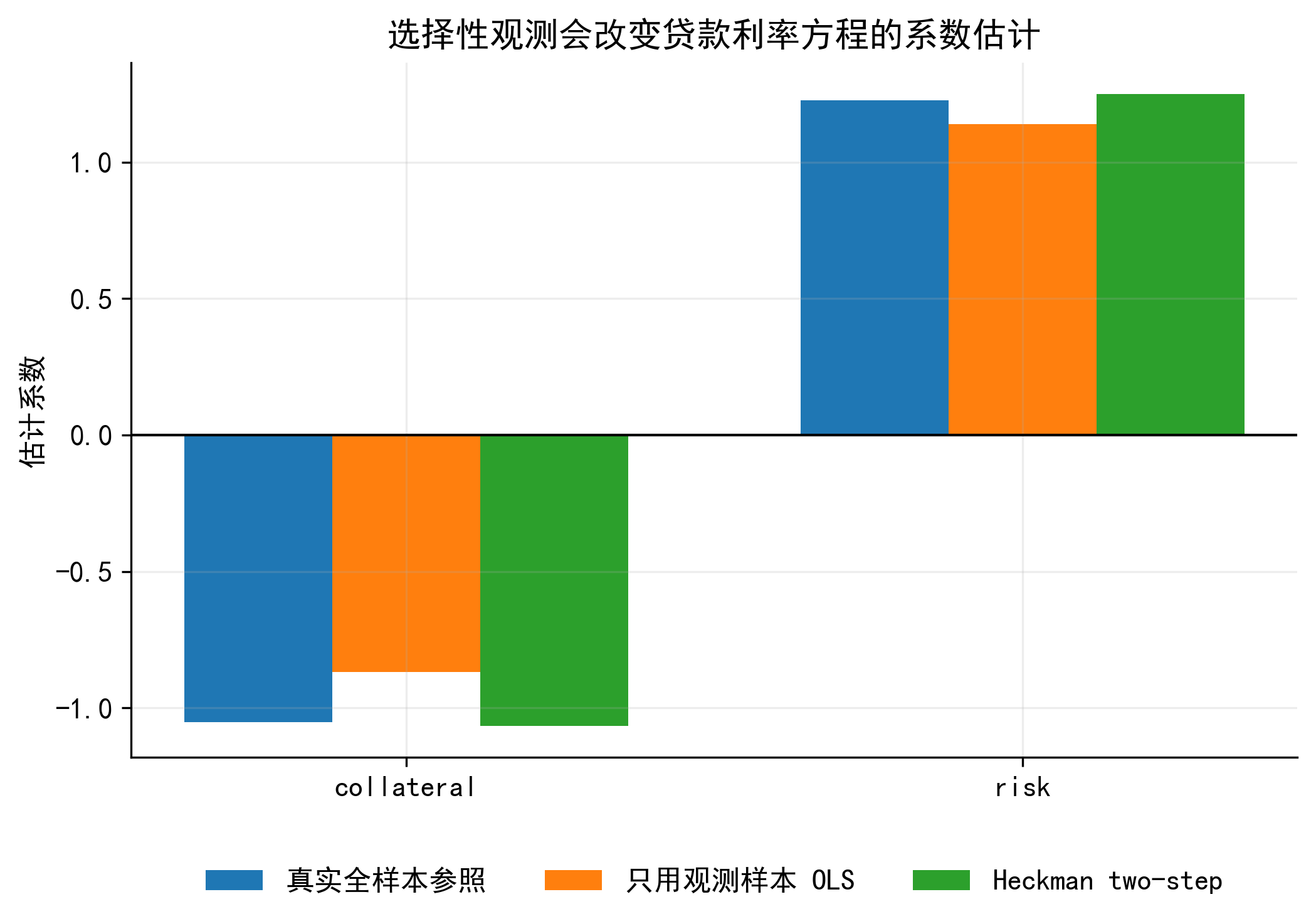
在本章的模拟数据中,我们知道真实机制:
\[
D_i^*
=
\gamma_0
+\gamma_1 collateral_i
+\gamma_2 bank\_access_i
-\gamma_3 risk_i
+v_i
\]
\[
R_i
=
\beta_0
-\beta_1 collateral_i
+\beta_2 risk_i
+u_i
\]
而且设定 \(u_i\) 与 \(v_i\) 负相关。直观上,某些未观测因素提高企业获得贷款的可能性,同时降低贷款利率 (比如,企业管理能力强或拥有政治关联)。此时,只看贷款企业,样本会向 “更容易贷款、利率更低” 的企业倾斜。
在解释结果时,可以按下面的顺序:
选择方程 :解释哪些变量影响企业获得贷款;结果方程 :解释抵押能力和风险如何影响贷款利率;IMR 系数 :解释是否存在选择性观测;与 naive OLS 比较 :说明忽略选择机制会如何改变系数。
第二阶段中 \(\hat\lambda_i\) 的系数估计的是 \(\rho\sigma_u\) 。由于 \(\sigma_u>0\) ,其符号主要反映 \(\rho\) 的符号。
\(\hat\delta>0\) :使企业进入观测样本的未观测因素,也倾向于提高结果变量;\(\hat\delta<0\) :使企业进入观测样本的未观测因素,倾向于降低结果变量;\(\hat\delta\) 不显著:选择性观测未必是主要问题,但不能自动证明不存在选择问题。
在贷款利率例子中,若 \(\hat\delta<0\) ,可以解释为:一些未观测因素提高企业获得贷款的概率,同时降低其贷款利率。例如更好的银企关系、更高的信息透明度或更强的议价能力。
8. 排他性变量:为什么不能随便找一个变量?
Heckman 模型在没有排他性变量时也可以依靠非线性识别,但这种识别往往很弱。因此,实证研究中最好有一个能影响选择、但不直接影响结果的变量。
本章中,\(bank\_access_i\) 是候选排他性变量。它进入选择方程:
\[
D_i^*
=
\gamma_0
+\gamma_1 collateral_i
+\gamma_2 bank\_access_i
-\gamma_3 risk_i
+v_i
\]
但不进入贷款利率方程:
\[
R_i
=
\beta_0
-\beta_1 collateral_i
+\beta_2 risk_i
+u_i
\]
这背后的经济逻辑是:
贷款可得性主要影响企业能否接触银行并进入贷款审批流程;在已经获得贷款资格、并控制抵押能力和风险之后,它不应直接影响企业的贷款利率。例如,具有政治关联的企业更容易获得银行贷款,但贷款利率还需要根据银行的风险评估和议价结果来决定。换言之,「有关系」只能确保企业可以进入银行的大门,但贷款利率还要看企业的抵押能力和风险。
一个变量是否适合作为排他性变量,不能只看它在第一阶段是否显著。它必须满足两个条件:
相关性 :它确实影响选择过程;排他性 :它不应直接影响结果变量,只能通过选择过程影响结果。
在本章案例中,\(bank\_access_i\) 的排他性并非天然成立。如果银行可得性同时代表当地银行竞争程度,那么它可能直接影响贷款利率。此时,研究者需要进一步控制市场竞争、地区金融发展水平,或者寻找更具体的制度性变量。
9. 与 Two-part model 的区别
05 章中的 Two-part model 和本章的 Heckman 模型都包含一个“是否发生”的方程,但二者解释的是不同问题。
未参与者的结果
结果为 0
结果不可观测
主例
贷款金额
贷款利率
第一阶段
是否获得贷款
是否获得贷款
第二阶段
获得贷款后贷多少
获得贷款后的利率如何决定
关键风险
两个机制被错误地合并
只看被选择样本导致偏误
是否需要排他性变量
不一定,但有助于解释
非常重要
因此,面对同一企业信贷背景,模型选择取决于研究对象:
如果研究贷款金额,未贷款企业的贷款金额可以记为 0,Two-part model 是自然选择;
如果研究贷款利率,未贷款企业的利率不可观测,Heckman selection 更合适。
10. Stata 实现示例
在自己的数据中,如果变量名与本章一致,可以使用如下形式:
two -step:企业贷款利率的选择性观测"./data/heckman_loan_sim.csv" , clear heckman loan_rate collateral risk, /// /// heckman loan_rate collateral risk, /// /// mle predict xb_outcome, xb predict mills, mills
two -step:企业贷款利率的选择性观测"D:\github_lianxh\dsfin\Lecture\limit_dep_heckman" "./data/heckman_credit_sim.csv" , clear heckman loan_rate collateral risk, /// ///
D:\github_lianxh\dsfin\Lecture\limit_dep_heckman
(encoding automatically selected: ISO-8859-1)
(11 vars, 3,000 obs)
Heckman selection model -- two-step estimates Number of obs = 3,000
(regression model with sample selection) Selected = 1,763
Nonselected = 1,237
Wald chi2(2) = 2619.50
Prob > chi2 = 0.0000
------------------------------------------------------------------------------
| Coefficient Std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
loan_rate |
collateral | -1.066 0.092 -11.55 0.000 -1.246 -0.885
risk | 1.249 0.024 51.17 0.000 1.202 1.297
_cons | 6.169 0.063 98.22 0.000 6.046 6.292
-------------+----------------------------------------------------------------
loan |
collateral | 1.307 0.133 9.81 0.000 1.046 1.568
risk | -0.723 0.032 -22.38 0.000 -0.786 -0.660
bank_access | 0.841 0.035 24.22 0.000 0.773 0.910
_cons | -0.238 0.063 -3.75 0.000 -0.362 -0.113
-------------+----------------------------------------------------------------
/mills |
lambda | -0.474 0.058 -8.23 0.000 -0.586 -0.361
-------------+----------------------------------------------------------------
rho | -0.57324
sigma | .82621512
------------------------------------------------------------------------------
heckman loan_rate collateral risk, /// /// mle
Iteration 0: Log likelihood = -3403.658
Iteration 1: Log likelihood = -3403.3422
Iteration 2: Log likelihood = -3403.3418
Heckman selection model Number of obs = 3,000
(regression model with sample selection) Selected = 1,763
Nonselected = 1,237
Wald chi2(2) = 2931.05
Log likelihood = -3403.342 Prob > chi2 = 0.0000
------------------------------------------------------------------------------
| Coefficient Std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
loan_rate |
collateral | -1.048 0.091 -11.57 0.000 -1.226 -0.870
risk | 1.242 0.023 54.06 0.000 1.197 1.287
_cons | 6.144 0.057 107.32 0.000 6.031 6.256
-------------+----------------------------------------------------------------
loan |
collateral | 1.334 0.132 10.10 0.000 1.075 1.593
risk | -0.722 0.032 -22.68 0.000 -0.784 -0.659
bank_access | 0.844 0.034 24.62 0.000 0.777 0.911
_cons | -0.251 0.063 -3.99 0.000 -0.374 -0.128
-------------+----------------------------------------------------------------
/athrho | -0.600 0.070 -8.56 0.000 -0.738 -0.463
/lnsigma | -0.197 0.020 -9.85 0.000 -0.237 -0.158
-------------+----------------------------------------------------------------
rho | -0.537 0.050 -0.628 -0.432
sigma | 0.821 0.016 0.789 0.854
lambda | -0.441 0.046 -0.532 -0.350
------------------------------------------------------------------------------
LR test of indep. eqns. (rho = 0): chi2(1) = 69.24 Prob > chi2 = 0.0000
predict xb_outcome, xb predict mills, mills
如果希望用 Stata 自带数据理解 Heckman 的基本语法,可以用 webuse mroz 导入 Mroz 数据集。该数据集源自 Mroz (1987) 的研究,包含了美国女性的劳动参与和工资信息。我们可以把 inlf 作为选择方程的被解释变量 (inlf = 1 表示参与劳动市场;inlf = 0 未进入劳动市场),wage 作为结果方程的被解释变量,其他变量如 educ、exper、age 等作为解释变量。
这里,我们选择了三个识别变量:nwifeinc (= (faminc - wage*hours)/1000,它表示家庭收入减去女性劳动收入的部分,以千美元为单位)、kidslt6 (6 岁以下孩子的数量)、kidsge6 (6 岁及以上孩子的数量)。
显然,这些变量会影响女性是否参与劳动市场,但在控制了教育、经验和年龄后,它们不太可能直接影响女性的工资水平:公司老板不会因为一个女性有更多的孩子就直接给她更高或更低的工资;也不会因为一个女性的家庭收入更高就直接调整她的工资。
webuse "mroz" , clear heckman wage educ exper age , /// ///
Heckman selection model -- two-step estimates Number of obs = 753
(regression model with sample selection) Selected = 428
Nonselected = 325
Wald chi2(3) = 54.08
Prob > chi2 = 0.0000
------------------------------------------------------------------------------
| Coefficient Std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
wage |
educ | 0.549 0.076 7.18 0.000 0.400 0.699
exper | 0.059 0.036 1.64 0.101 -0.011 0.129
age | -0.015 0.029 -0.52 0.605 -0.073 0.042
_cons | -3.471 1.321 -2.63 0.009 -6.060 -0.881
-------------+----------------------------------------------------------------
inlf |
educ | 0.134 0.025 5.32 0.000 0.084 0.183
exper | 0.070 0.008 9.27 0.000 0.055 0.085
age | -0.056 0.008 -6.66 0.000 -0.072 -0.039
nwifeinc | -0.012 0.005 -2.41 0.016 -0.021 -0.002
kidslt6 | -0.874 0.118 -7.44 0.000 -1.105 -0.644
kidsge6 | 0.035 0.043 0.80 0.422 -0.050 0.119
_cons | 0.580 0.496 1.17 0.243 -0.393 1.552
-------------+----------------------------------------------------------------
/mills |
lambda | 1.054 0.773 1.36 0.173 -0.462 2.569
-------------+----------------------------------------------------------------
rho | 0.33160
sigma | 3.1784469
------------------------------------------------------------------------------
heckman wage educ exper age , /// /// mle nolog
Heckman selection model Number of obs = 753
(regression model with sample selection) Selected = 428
Nonselected = 325
Wald chi2(3) = 142.49
Log likelihood = -1437.813 Prob > chi2 = 0.0000
------------------------------------------------------------------------------
| Coefficient Std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
wage |
educ | 0.613 0.074 8.24 0.000 0.467 0.758
exper | 0.197 0.023 8.38 0.000 0.151 0.243
age | -0.092 0.023 -3.95 0.000 -0.138 -0.046
_cons | -4.458 1.355 -3.29 0.001 -7.113 -1.804
-------------+----------------------------------------------------------------
inlf |
educ | 0.156 0.021 7.51 0.000 0.115 0.196
exper | 0.049 0.006 7.96 0.000 0.037 0.060
age | -0.027 0.006 -4.15 0.000 -0.039 -0.014
nwifeinc | -0.007 0.002 -2.95 0.003 -0.011 -0.002
kidslt6 | -0.167 0.053 -3.14 0.002 -0.272 -0.063
kidsge6 | 0.020 0.023 0.91 0.364 -0.024 0.065
_cons | -1.027 0.380 -2.70 0.007 -1.772 -0.282
-------------+----------------------------------------------------------------
/athrho | 2.667 0.225 11.87 0.000 2.227 3.107
/lnsigma | 1.394 0.039 35.42 0.000 1.317 1.471
-------------+----------------------------------------------------------------
rho | 0.990 0.004 0.977 0.996
sigma | 4.032 0.159 3.733 4.355
lambda | 3.993 0.165 3.670 4.316
------------------------------------------------------------------------------
LR test of indep. eqns. (rho = 0): chi2(1) = 119.86 Prob > chi2 = 0.0000
Stata 扩展命令与模型地图
Heckman selection model 是一个基础框架。实际研究中,结果变量类型和选择机制可能更复杂,可以考虑以下命令或模型:
连续结果变量存在样本选择
heckman标准 Heckman selection model
二元结果变量存在样本选择
heckprobitoutcome 为 Probit,带选择机制
有序结果变量存在样本选择
heckoprobitoutcome 为 ordered probit,带选择机制
计数结果变量存在样本选择
heckpoissonoutcome 为 Poisson,带选择机制
内生切换回归
movestay不同 regime 下结果方程不同
多方程混合模型
cmp用户扩展命令,适合更复杂的递归多方程结构
如果需要应用于面板数据,可以考虑使用 xtheckman 命令。详情可以参考如下推文:
扩展命令可以处理更复杂的因变量类型和方程结构,但不能自动解决识别问题。选择方程和结果方程的经济含义、排他性变量的合理性、样本产生过程的解释,仍然是模型可信度的核心。
一些提示词
这里提供一些提示词,用于针对你的数据生成 Python 或 Stata 代码。你可以用最后一组提示词来评估你的排他性变量是否有说服力。
我正在分析一个 Heckman 选择模型。结果变量是 结果变量名,只有在 选择变量名=1 时才可观测。结果方程解释变量包括 结果方程变量列表,选择方程解释变量包括 选择方程变量列表,其中 排他性变量名 只进入选择方程。请帮我生成 Python 代码,完成 Probit 第一阶段、inverse Mills ratio 计算、第二阶段 OLS 回归、结果表整理和基本解释。代码需要包含中文注释,并假定数据保存在 pandas DataFrame df 中。
我正在使用 Stata 估计 Heckman 选择模型。结果变量是 结果变量名,选择变量是 选择变量名,结果方程解释变量包括 结果方程变量列表,选择方程解释变量包括 选择方程变量列表。其中 排他性变量名 只进入选择方程。请帮我生成 heckman 的两阶段估计和极大似然估计代码,并使用 esttab 输出回归表。代码需要使用 /// 换行,并添加中文注释。
我正在为 Heckman 选择模型设计排他性变量。研究问题是 研究问题,结果变量是 结果变量,选择变量是 选择变量,候选排他性变量是 变量名。请从经济机制、制度背景、可能的直接效应、需要加入的控制变量和稳健性检验五个角度,评估这个变量是否适合作为选择方程中的排他性变量。
11. 本章小结
Heckman 模型的核心不是“有一个选择方程”,而是结果变量只在被选择样本中可观测。企业信贷案例中,贷款金额和贷款利率的区别非常适合说明这一点:
贷款金额:未贷款企业可以记为 \(B_i=0\) ;
贷款利率:未贷款企业没有贷款,\(R_i\) 不可观测;
若直接在贷款企业中估计利率方程,样本不是随机子样本;
若选择方程误差与利率方程误差相关,OLS 会出现选择性偏误;
IMR 是被选择样本中误差项条件均值的修正项;
排他性变量是 Heckman 设计中最需要认真论证的部分。
从建模思路上看,本章延续了 04 章 Tobit 的基本逻辑:先说明潜在机制,再说明观测机制,最后根据观测机制写出合适的似然或修正方程。只要这条链条清楚,Heckman 模型就不再是一个机械套用的命令,而是一个有明确经济含义的研究设计。
参考文献
Heckman, J. J. (1979). Sample selection bias as a specification error. Econometrica, 47(1), 153–161. Link , PDF , Google .
Mroz, T. A. (1987). The sensitivity of an empirical model of married women’s hours of work to economic and statistical assumptions. Econometrica, 55(4), 765–799. Link , PDF , Google .
Stiglitz, J. E., & Weiss, A. (1981). Credit rationing in markets with imperfect information. American Economic Review, 71(3), 393–410. Link , PDF , Google .
Petersen, M. A., & Rajan, R. G. (1994). The benefits of lending relationships: Evidence from small business data. The Journal of Finance, 49(1), 3–37. Link , PDF , Google .
Vella, F. (1998). Estimating models with sample selection bias: A survey. Journal of Human Resources, 33(1), 127–169. Link , PDF , Google .
附录 A:IMR 推导的直观版本
设选择方程误差 \(v_i\sim N(0,1)\) ,选择条件为:
\[
D_i=1
\Longleftrightarrow
v_i>-z_i'\gamma
\]
在正态分布中,若只保留超过某个阈值的样本,误差项的条件均值不再为 0。对标准正态变量 \(v\) ,有:
\[
E(v\mid v>c)
=
\frac{\phi(c)}
{1-\Phi(c)}
\]
令 \(c=-z_i'\gamma\) ,利用 \(\phi(-a)=\phi(a)\) 和 \(1-\Phi(-a)=\Phi(a)\) ,得到:
\[
E(v_i\mid D_i=1,z_i)
=
\frac{\phi(z_i'\gamma)}
{\Phi(z_i'\gamma)}
=
\lambda(z_i'\gamma)
\]
如果 \(u_i\) 与 \(v_i\) 相关,则:
\[
E(u_i\mid D_i=1,z_i)
=
\rho\sigma_u
\lambda(z_i'\gamma)
\]
这就是第二阶段中需要加入 IMR 的原因。
附录 B:Heckman two-step 的解释模板
在论文或作业中,可以这样解释 Heckman 结果:
第一阶段结果显示,抵押能力和银行可得性显著提高企业获得贷款的概率,而风险水平降低企业获得贷款的概率。这说明贷款样本不是随机形成的。第二阶段中,抵押能力降低贷款利率,风险水平提高贷款利率。加入 IMR 后,核心变量系数与直接 OLS 相比发生变化,说明只在贷款企业样本中估计利率方程可能受到选择性观测的影响。IMR 系数为负,意味着一些提高企业获得贷款概率的未观测因素也倾向于降低贷款利率。
如果 IMR 不显著,表述应更谨慎:
IMR 系数不显著,说明在当前设定和样本中,未发现强烈的选择性观测修正证据。但这并不自动证明选择问题不存在,因为 Heckman 模型的识别依赖于排他性变量的合理性以及联合正态等模型假设。