30 非线性调节效应怎么做?部分线性函数型面板数据模型
Du, K., Cheng, Y., & Yao, X. (2021). Environmental regulation, green technology innovation, and industrial structure upgrading: The road to the green transformation of Chinese cities. Energy Economics, 98, 105247. Link, PDF, Replication, Google, -cited-.
- 方法介绍:Du, K., Zhang, Y., & Zhou, Q. (2020). Fitting partially linear functional-coefficient panel-data models with Stata. The Stata Journal, 20(4), 976–998. Link, PDF, Google. -cited-, -Github-
30.1 简介
在传统的调节效应检验中,我们通常在回归方程中加入交乘项 \(Z_{it} \times U_{it}\) 。但是这种传统交互形式可能无法准确地捕捉 \(Z_{it}\) 对 \(Y_{it}\) 的动态或非线性影响。为了克服这一限制,部分线性函数型面板数据模型应运而生。
部分线性函数型面板数据模型结合了线性模型和非线性函数型系数的优点,允许模型中的某些系数随解释变量的变化而平滑变动。这种灵活性使得模型能够更准确地捕捉数据中的非线性关系,进而提升预测和解释的精度。
xtplfc_Stata 是一个专门用于估计部分线性函数型面板数据模型的 Stata 模块。该模块包含以下几个主要程序:
xtplfc:用于估计部分线性函数型静态面板数据模型。ivxtplfc:用于估计包含内生变量的部分线性函数型静态面板数据模型。xtdplfc:用于估计部分线性函数型动态面板数据模型。
本文将主要介绍第一个命令,其余两个命令的使用方法基本相同,详情可以使用 help ivxtplfc 或 help xtdplfc 查看命令模拟案例。
30.2 理论背景
为研究 \(Z_{it}\) 对 \(Y_{it}\) 的影响,我们首先考虑下式所示的线性模型。
\[ Y_{it} = \gamma Z_{it} + \beta_0 X_{it} + \delta_i + \mu_{it} \quad (1) \]
其中,\(Z_{it}\) 表示核心解释变量,\(Y_{it}\) 是被解释变量,\(X_{it}\) 是控制变量。
传统交互形式:
\[ Y_{it} = \gamma_1 Z_{it} + \gamma_2 Z_{it} \times U_{it} + \beta_0 X_{it} + \delta_i + \mu_{it} \quad (2) \]
\(Z_{it}\) 对 \(Y_{it}\) 的边际影响为:
\[ M_{it}^{Y\!Z} = \gamma_1 + \gamma_2 U_{it} \quad (3) \]
然而,这种设定隐含的假设是,\(M_{it}^{Y\!Z}\) 与 \(U_{it}\) 之间存在多元线性关系,无法捕捉二者之间可能存在的非线性关系,如 \(J\) 型关系,甚至是 \(S\) 型关系。
当然,我们可以考虑将 \(M_{it}^{Y\!Z}\) 设定为如下一般化的形式:
\[ \gamma(U_{it}) = \theta_0 + \theta_1 U_{1it} + \theta_2 U_{2it} + \cdots + \theta_k U_{kit} \quad (4) \]
其中,\(U_{2it}\) 和 \(U_{3it}\) 可以分别设定为 \(U_{1it}^2\) 和 \(U_{1it}^3\),以捕捉可能存在非线性关系。不过,即便如此,我们也在模型设定之初便认为限定了 \(\gamma(U_{it})\) 的具体模型形式,仍然可能存在模型设定偏误。
新型非参数设定:
为克服构建交互项方法的不足,我们让 \(Z_{it}\) 以 \(U_{it}\) 的函数作为系数进入模型。于是我们得到:
\[ Y_{it} = \gamma(U_{it}) Z_{it} + \beta_0 X_{it} + \delta_i + \mu_{it} \quad (5) \]
在这种设定下,\(Z\) 对 \(Y\) 的边际影响可以表示为:
\[ M_{it}^{Y\!Z} = \frac{\partial(Y_{it})}{\partial(Z_{it})} = \gamma(U_{it}) \quad (6) \]
为此,Li et al. (2002) 提出了非参数估计方法,以避免模型误设偏误。An et al. (2016) 进一步将 Li et al. (2002) 的模型从截面数据情形扩展到包含固定效应的面板数据情形下,称之为「部分线性变系数面板模型」。Du et al. (2020) 编写了相应的 Stata 命令 xtplfc, ivxtplfc 和 xtdplfc,并在 Du et al. (2021) 中应用该方法研究中国城市层面的环境规制与绿色创新之间的关系。
30.3 估计方法
An et al.(2016)建议采用如下步骤估计模型 (5)。
第一步,进行一阶差分,消除固定效应 \(\delta_i\)。
\[ \Delta Y_{it} = \Delta \gamma(U_{it}) Z_{it-1} + \beta_0 \Delta X_{it-1} + \Delta \mu_{it} \quad (7) \]
第二步,函数系数的近似。 用 \(k\) 个基函数的线性组合近似变系数函数 \(\gamma(U_{it})\):
\[ p(U_{it})^T \theta = \left[ p_1(U_{it}), \ldots, p_k(U_{it}) \right]^T \theta = \left[ \theta_1, \ldots, \theta_k \right]^T p(U_{it}) \quad (8) \]
其中,\(p(U_{it})\) 是 \(k \times 1\) 的基函数向量,\(\theta\) 是 \(k \times 1\) 的未知参数向量。当 \(k\) 增大时,存在 \(p_i(U_{it})\) 的线性组合能够很好地近似任何光滑函数 \(\gamma(U_{it})\) ,并且近似均方误差(MSE)尽可能小。
代入差分模型 (7) 后,可得:
\[ \Delta Y_{it} = \Delta Z_{it-1} p(U_{it})^T \theta + \beta_0 \Delta X_{it-1} + \Delta \epsilon_{it} \quad (9) \]
其中,\(\Delta \epsilon_{it}\) 表示序列近似误差:
\[ \Delta \epsilon_{it} = \Delta \mu_{it} + \Delta(\gamma(U_{it})Z_{it-1}) - \Delta(Z_{it-1}p(U_{it})^T)\theta \]
第三步,最小二乘估计。
\[ \left[ \begin{array}{c} \hat{\beta}_0 \\ \hat{\theta} \end{array} \right] = \left( \Delta X^T \Delta X \right)^{-1} \Delta X^T \Delta Y \quad (10) \]
其中, - \(\Delta Y = \left[ \Delta Y_{12}, \ldots, \Delta Y_{NT} \right]^T\); - \(\Delta X = \left[ \Delta X_{11}, \ldots, \Delta Z_{NT-1} p(U_{NT-1})^T \right]^T\)。
30.3.1 样条基函数估计(Sieve Estimation)
在上述估计过程中,为估计未知函数 \(\gamma(U)\),我们使用 样条基函数近似法(Sieve 方法)。
直观解释: 样条(spline)是一种将区间划分为若干小段,在每段上使用低阶多项式进行拟合的方法。样条在每段区间连接处保持连续及光滑(如一阶或二阶导数连续),能很好地逼近任意光滑函数 \(\gamma(U)\),并通过控制结点数量避免过拟合。
30.3.1.1 技术步骤:
选择基函数集:
设定 \(p\) 个样条基函数 \(h_1(U), h_2(U), ..., h_p(U)\),记为向量:
\[ h(U) = \left[ h_1(U), h_2(U), \ldots, h_p(U) \right]^T \quad (11) \]
线性组合近似函数系数项:
\[ \gamma(U) \approx h(U)^T \theta = \sum_{j=1}^{p} \theta_j h_j(U) \quad (12) \]
将原模型写为线性形式:
\[ Y_{it} \approx Z_{it} \cdot h(U_{it})^T \theta + \beta^T X_{it} + \alpha_i + \varepsilon_{it} \quad (13) \]
记号简化为 \(H_{it}\):
设 \(H_{it} = Z_{it} \cdot h(U_{it})\),则模型变为:
\[ Y_{it} = H_{it}^T \theta + \beta^T X_{it} + \alpha_i + \varepsilon_{it} \quad (14) \]
OLS 或 GMM 估计: 剔除个体固定效应 \(\alpha_i\) 后,使用 OLS 或 GMM 估计 \(\theta\) 和 \(\beta\)。
30.3.2 边际效应估计
完成上述估计后,可以采用下式得到 (6) 式中 \(Z_{it}\) 的边际效应:
\[ \hat{\gamma}(U_{it}) = p(U_{it})^T \hat{\theta} \quad (15) \]
30.3.2.1 边际效应的置信区间计算
我们希望为估计函数 \(\gamma(U)\) 提供点估计与置信带,用于展示在不同 \(U\) 水平下边际效应的统计显著性。
步骤如下:
估计边际效应函数:
\[ \hat{\gamma}(U) = h(U)^T \hat{\theta} \quad (16) \]
估计残差项:
\[ \hat{\varepsilon}_{it} = Y_{it} - \hat{\gamma}(U_{it}) Z_{it} - \hat{\beta}^T X_{it} \quad (17) \]
构造协方差矩阵估计 \(\hat{\Sigma}\):
若 \(H\) 是所有 \(H_{it}\) 的堆叠矩阵,则:
\[ \hat{\Sigma} = (H^T H)^{-1} H^T \text{diag}(\hat{\varepsilon}^2) H (H^T H)^{-1} \quad (18) \]
估计 \(\gamma(U)\) 在 \(U_0\) 处的标准误:
\[ \widehat{se}[\gamma(U_0)] = \sqrt{h(U_0)^T \hat{\Sigma} h(U_0)} \quad (19) \]
构建 \(95\%\) 的置信区间:
\[ \left[ \hat{\gamma}(U_0) \pm 1.96 \cdot \widehat{se}[\gamma(U_0)] \right] \quad (20) \]
30.3.2.2 总结:PLFC 模型的优势
- 刻画连续非线性效应:边际效应随 PGDP 光滑变化
- 避免门槛模型的断点与先验设定问题
- 具备良好的解释力与可视化能力
- 适用于异质性显著、样本量大的面板数据结构
30.4 Stata 实现
30.4.1 安装 xtplfc 命令
可以执行如下命令安装:
view net sj 20-4 st0624 // 查看程序清单
net install st0624.pkg, all replace // 安装
help xtplfc // 帮助文档30.4.2 命令语法
\[Y_{it} = \gamma(U_{it}) Z_{it} + \beta_0 X_{it} + \delta_i + \mu_{it} \quad (5)\]
xtplfc 命令的语法格式如下:
xtplfc varlist,
zvars(varlist)
uvars(varname)
generate(string)
[ options ]必填项:
varlist:填入 \(Y_{it}\) 和控制变量zvars(varlist):指定具有函数系数的变量列表 \(Z_{it}\)。uvars(varlist):指定(连续)变量 \(U_{it}\),这些变量以交互形式进入函数系数。generate(prefix):指定一个前缀,用于存储函数系数拟合值 \(\hat{\gamma}(U_{it})\),参见 (10) 式。
可选项:
te:指定是否包含时间固定效应。power(numlist):指定样条的幂。默认值为3。nknots(numlist):指定用于样条插值的结点数量。默认值为2。quantile:指定基于经验分位数创建结点。默认情况下,结点是通过等距规则生成的。maxnknots(numlist):指定用于进行最小二乘交叉验证(LSCV)的最大结点数量。minnknots(numlist):指定用于执行LSCV的最小结点数量。默认值为2。brep(#):指定bootstrap复制的次数。默认值为brep(200)。建议选择合适的复制次数。wild:指定使用wild bootstrap。默认情况下,执行带有选项cluster(panelvar)的残差bootstrap。predict(prspec):使用指定的变量名存储条件均值和固定效应的预测值。该选项接受变量列表或存根。第一个变量名对应于预测的条件均值。第二个名称对应于固定效应。level(#):设置置信水平。默认值为95。fast:使用Mata函数加速计算。tenfoldcv:使用十折交叉验证代替LSCV。
30.5 应用:Du et al. (2021, EE)
Du et al. (2021) 中应用基于部分线性模型的变系数面板数据模型 (xtplfc),研究中国城市层面的环境规制与绿色创新之间的关系
30.5.1 简介
环境管制 (\(Z\)) 可能会促进 绿色技术创新 (\(Y_1\)) 和 产业结构升级 (\(Y_2\)),但作用效果会受到 经济发展水平 (调节变量 \(U\)) 的影响。
政策启示:在经济欠发达地区或经济发展水平较低的阶段,不宜过度事实环境管制。
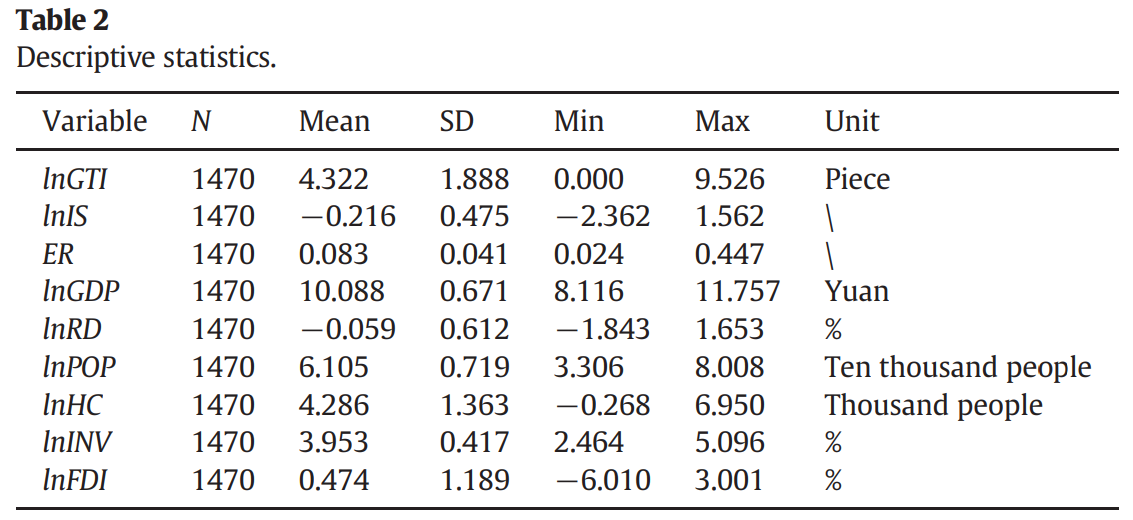
30.5.2 基本回归结果
作者先采用固定效应模型估计了平均效果:
\[ \begin{aligned} \ln G I_{i t}= & \gamma E R_{i t-1}+\beta_1 \ln R D_{i t-1}+\beta_2 \ln P O P_{i t-1} \\ & +\beta_3 \ln H C_{i t-1}+\beta_4 \ln I N V_{i t-1}+\beta_5 \ln F D I_{i t-1}+\delta_i+\mu_{i t} \end{aligned} \quad (11) \]
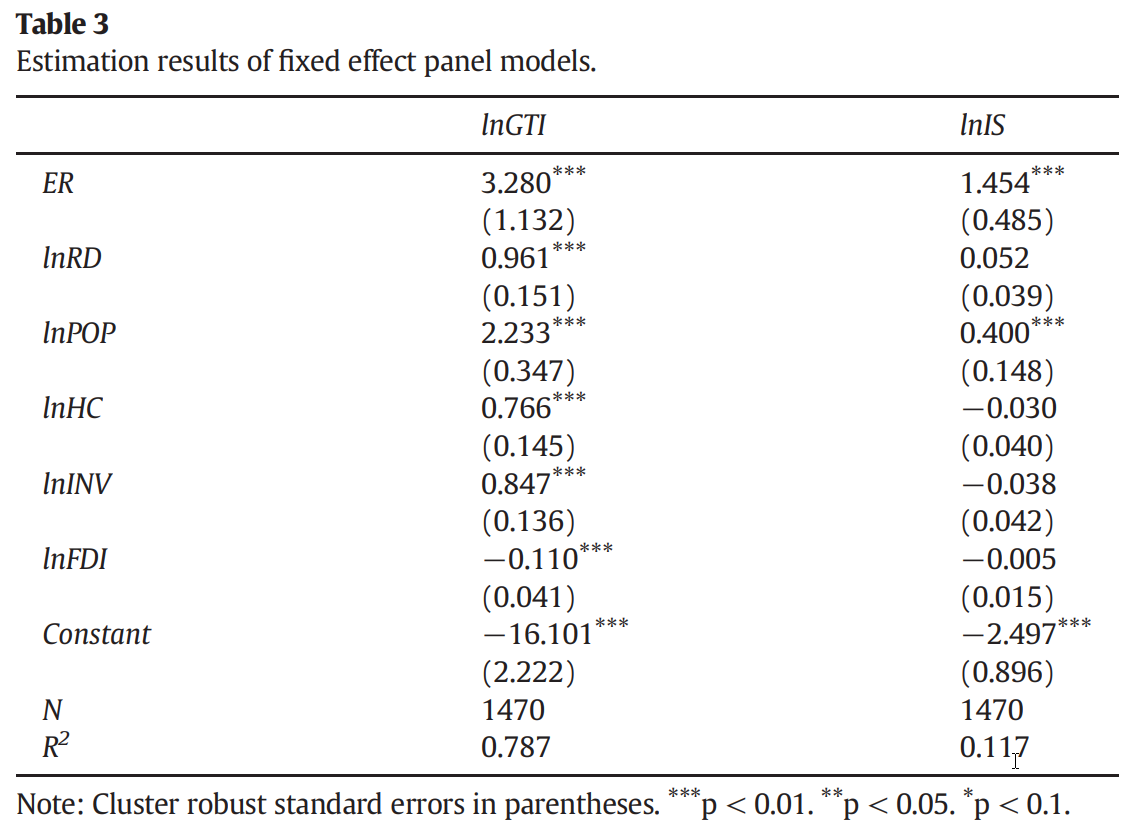
30.5.3 半参数系数可变模型设定
为研究环境规制(ER)对绿色技术创新和产业结构的影响,本文设定如下模型:
\[ Y_{i t}=\gamma\left(U_{i t-1}\right) Z_{i t-1}+\beta^{\prime} X_{i t-1}+\delta_i+\mu_{i t} \tag{12} \]
其中,
- \(Y_{it}\) 表示下列两个变量之一:
- InGTI:绿色技术创新 或 InIS:产业结构
- \(Z_{it-1}\):第 \(i\) 个城市在 \(t-1\) 时刻的环境管制水平 (ER)
- \(U_{it-1}\):经济发展水平,用人均 GDP 的对数衡量 (lnGDP)
- \(X_{it-1}\):控制变量,包括
- lnRD:科技与教育经费投入
- lnPOP:城市规模
- lnHC:人力资本
- lnINV:固定资产投资
- lnFDI:经济开放度
- \(\delta_i\):不可观测的个体固定效应
30.5.4 边际效应的截面差异
*use "ERdata.dta", clear
use "https://github.com/lianxhcn/data/raw/refs/heads/main/Du2021EE_ERdata.dta", clear
xtset cityno year
*---- Table 4, col (1)
xtplfc lngti lnrd lnpop lnhc lninv lnfdi, ///
zvars(er) ///
uvar(lngdp) ///
gen(fcoe_gti) maxnknots(20) brep(1000)
*-Notes:
* [1] 使用 xtplfc 命令进行函数系数估计,其中
* lner 是核心解释变量 (X)
* lngdp 是调节变量 (U),
* [2] gen(fcoe_gti) 生成预测值,用以记录 \gamma(U)
* [3] maxnknots(20) 设置最多 20 个结点进行平滑处理,
* [4] brep(1000):bootstrap 1000 次获取 SE
*---------- Figure 2
gen lb_gti = fcoe_gti_1 - 1.96*fcoe_gti_1_sd // 95% CI lower bound
gen ub_gti = fcoe_gti_1 + 1.96*fcoe_gti_1_sd // 95% CI upper bound
local plot1 "line fcoe_gti_1 lngdp, color(black) sort"
local plot2 "rarea lb_gti ub_gti lngdp, color(gs12) sort"
twoway (`plot2') (`plot1'), ///
legend(label(1 "95% CI") ///
label(2 "Functional coefficients") ///
ring(0) pos(5)) ///
xtitle(, margin(t+2)) ///
ytitle("Marginal effects: {&gamma} (lngdp)")
graph export "$out/Du2021_EE_Figure02.png", width(700) replace 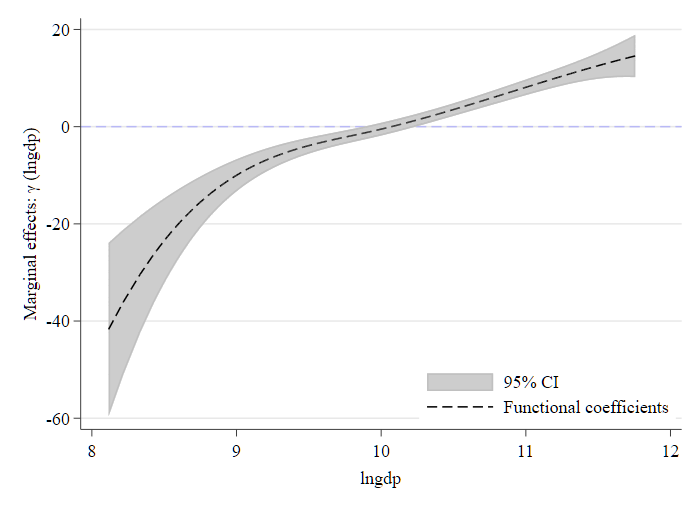
Fig. 2. Functional coefficients of ER with respect to ln(GTI).
\(Y_{it} = \ln (gti)\),\(Z_{it} = ER\);\(U_{it-1} = \ln (gdp)\)
根据图示结果,我们可以观察到:
- 在经济水平相对较低的城市中,环境规制措施反而会对绿色技术创新产生 抑制作用;
- 当城市的 lnGDP 值超过 10 时,即经济达到一定发展水平后,环境规制则转而成为推动绿色技术创新的重要因素。
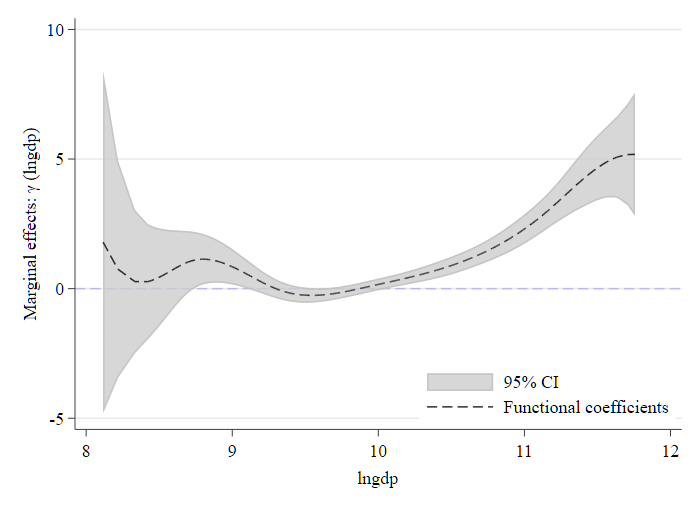
Fig. 3. Functional coefficients of ER with respect to IS (Industrial Structure).
\(Y_{it} = IS\),\(Z_{it} = ER\);\(U_{it-1} = \ln (gdp)\)
图 3 揭示环境规制与产业结构优化升级的关系:
- 在经济欠发达的城市中,环境规制并未能有效促进产业结构的优化升级;
- 然而,在经济较为发达的城市中,环境规制则展现出了积极的正向效果,有助于推动产业结构的优化与升级。
30.5.5 边际效应的时序差异
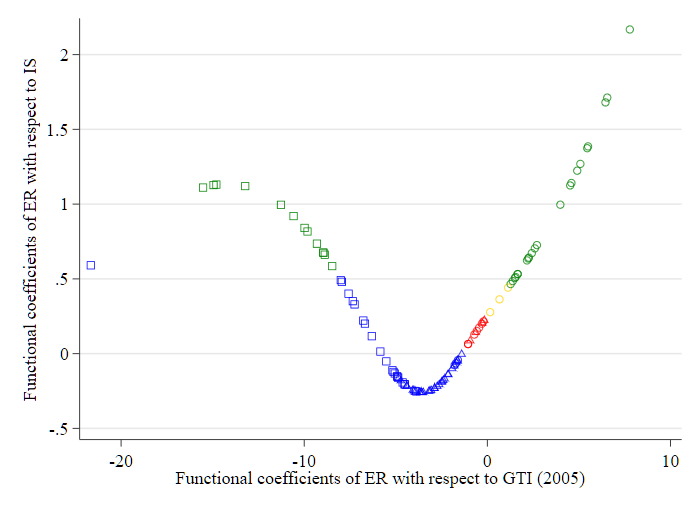
Figure 4 (a)
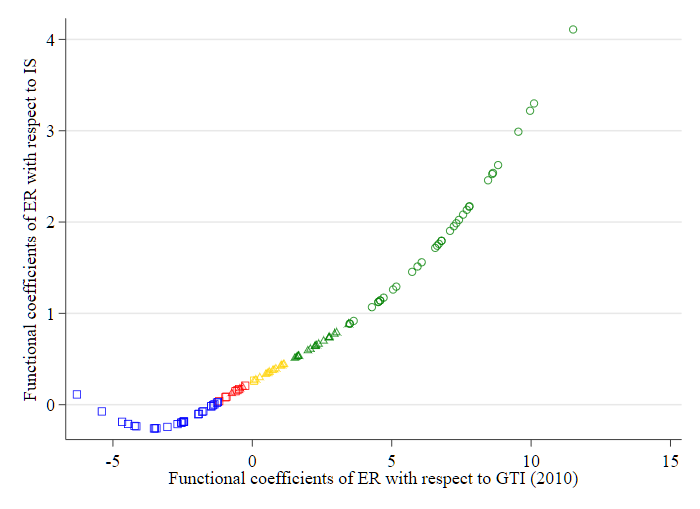
Figure 4 (b)
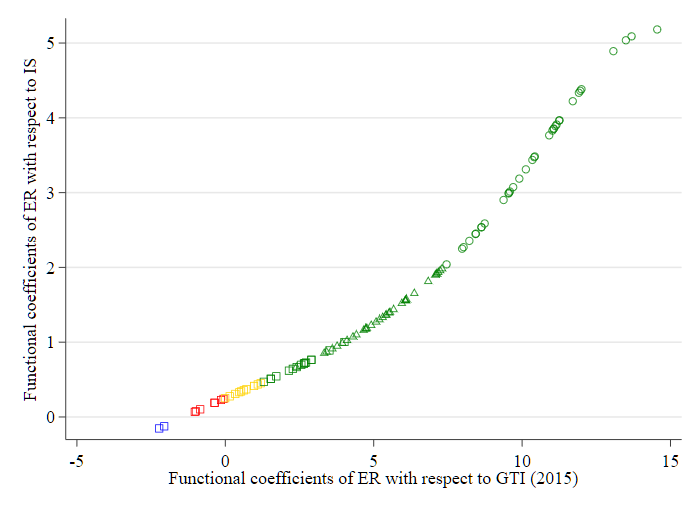
Figure 4 (c)
Fig. 4. - (a) Functional coefficients of ER in 2005. - (b) Functional coefficients of ER in 2010. - (c) Functional coefficients of ER in 2015.
注:
- \(\mathbf{\square}\) 表示实际人均 GDP 处于较低水平;
- \(\mathbf{\triangle}\) 表示实际人均 GDP 处于中等水平;
- \(\mathbf{\bigcirc}\) 表示实际人均 GDP 处于较高水平。
- \({\color{red}{红色}}\) 表示 ER 对 \(\operatorname{lnGTI}\) 和 \(\ln\) IS 的影响均不显著;
- \({\color{yellow}{黄色}}\) 表示 ER 对 InIS 有显著影响,但对 InGTI 的影响不显著;
- \({\color{blue}{蓝色}}\) 表示 ER 对 InGTI 有显著影响,但对 InIS 的影响不显著;
- \({\color{green}{绿色}}\) 表示 ER 对 InGTI 和 InIS 的影响均显著。
30.6 参考文献
本文的理论和实证部分主要参考下面的几篇文献,数据与代码可在论文的附录中下载。
Yonghong, A., Cheng, H., & Dong, L. (2016). Semiparametric Estimation of Partially Linear Varying Coefficient Panel Data Models. Essays in Honor of Aman Ullah, 47–65. Link, PDF, Google.
Du, K., Cheng, Y., & Yao, X. (2021). Environmental regulation, green technology innovation, and industrial structure upgrading: The road to the green transformation of Chinese cities. Energy Economics, 98, 105247. Link (rep), PDF, Google.
Du, C., Cao, Y., Ling, Y., Jin, Z., Wang, S., & Wang, D. (2024). Does manufacturing agglomeration promote green productivity growth in China? Fresh evidence from partially linear functional-coefficient models. Energy Economics, 131, 107352. Link , PDF, Google.
Du, K., Zhang, Y., & Zhou, Q. (2020). Fitting partially linear functional-coefficient panel-data models with Stata. The Stata Journal, 20(4), 976–998. Link, PDF, Google.
30.7 相关推文
- 任缘, 2024, 估计处理效应并提供非参数置信区间-xtteifeci, 连享会 No.1524.
- 吴小齐, 2023, Stata:如何理解非参数估计, 连享会 No.1287.
- 唐雪梅, 2023, Stata:面板变斜率检验-xthst, 连享会 No.1218.
- 孙晓艺, 2024, 论文复现:面板变系数模型及其在工资溢价和教育回报中的应用, 连享会 No.1371.
- 崔颖, 2020, RDD:断点回归的非参数估计及Stata实现, 连享会 No.159.
- 浦进博, 2024, Stata:非参数合成控制法命令—npsynth, 连享会 No.1458.
- 苗妙, 2020, 面板变系数模型:每家公司都有一个斜率, 连享会 No.486.